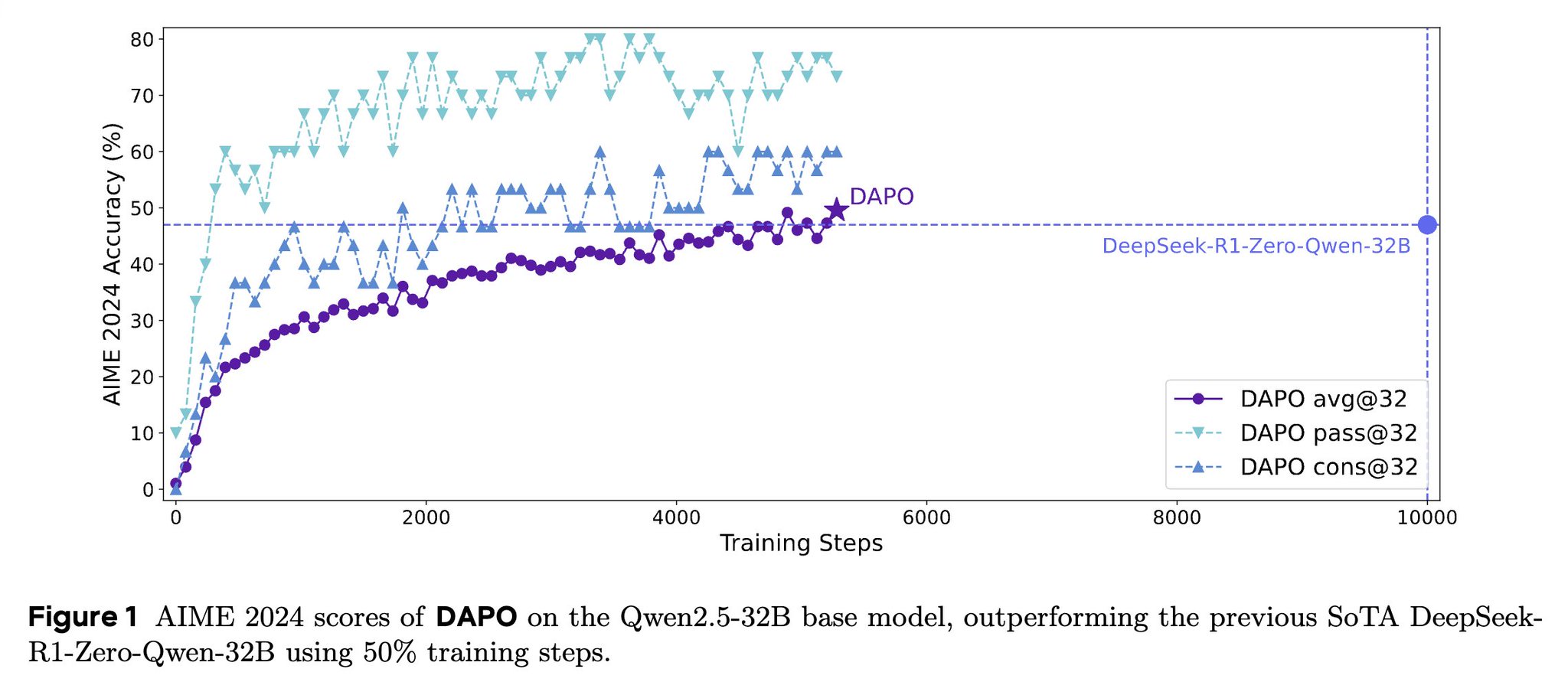
Reinforcement learning for LLMs—fully open-sourced DAPO trains Qwen2.5-32B with RL, hitting 50 points on AIME 2024, outperforming DeepSeek-R1-Zero after just 50% of the training steps. Open-source code & dataset
Improved training stability Trending #1 on alphaXiv
DAPO: Open-Source RL Training for Qwen2.5-32B LLMs
By
–