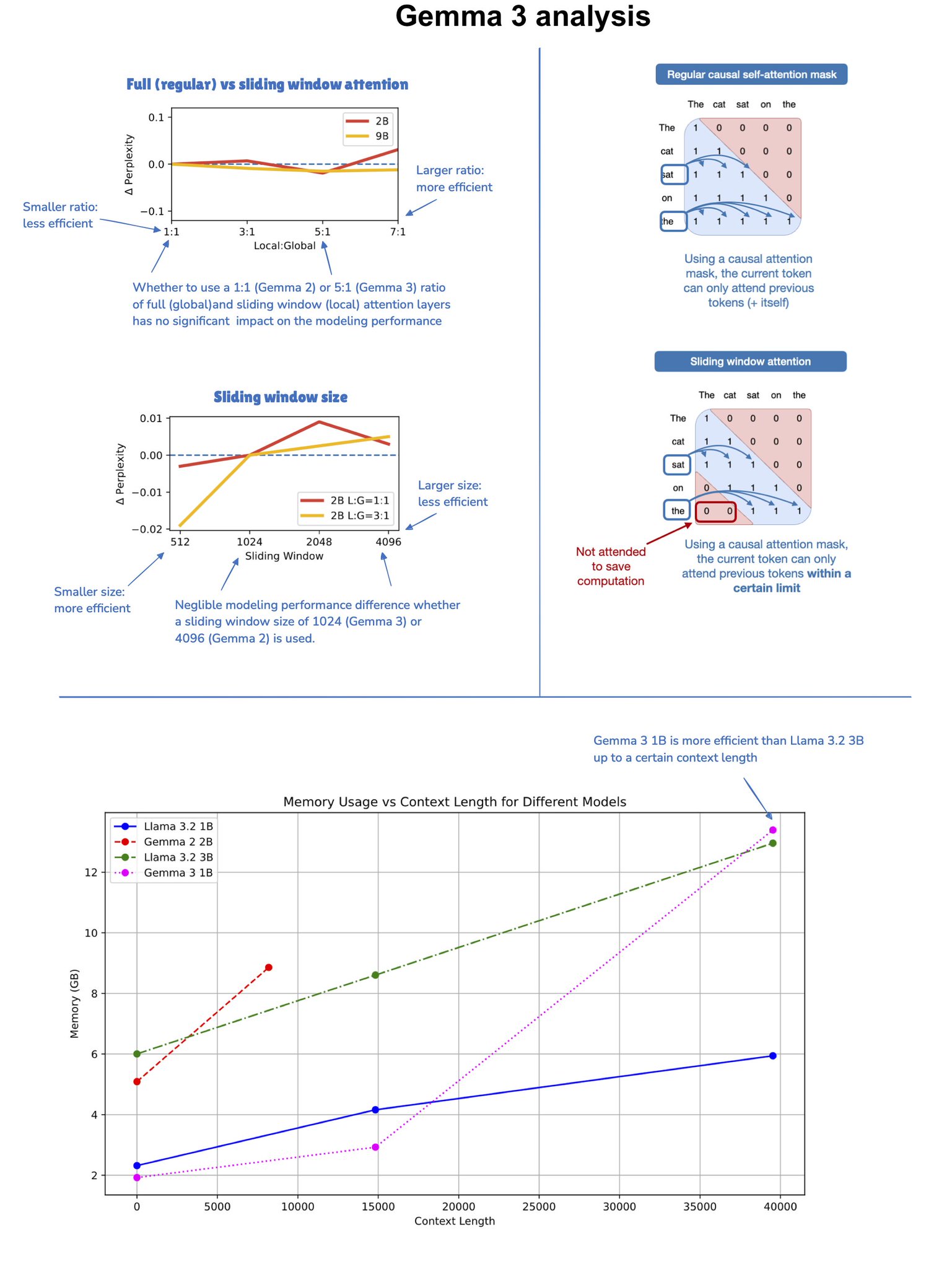
Just read through the Gemma 3 report and toyed around with the models a bit, and there are a bunch of interesting tidbits: 1. Vocab size. They again use a very large vocab: 262k token (in contrast, Llama 3 has ~1/2 the vocab size), which should make the model more friendly for
Gemma 3 Analysis: Large Vocabulary Size and Model Insights
By
–