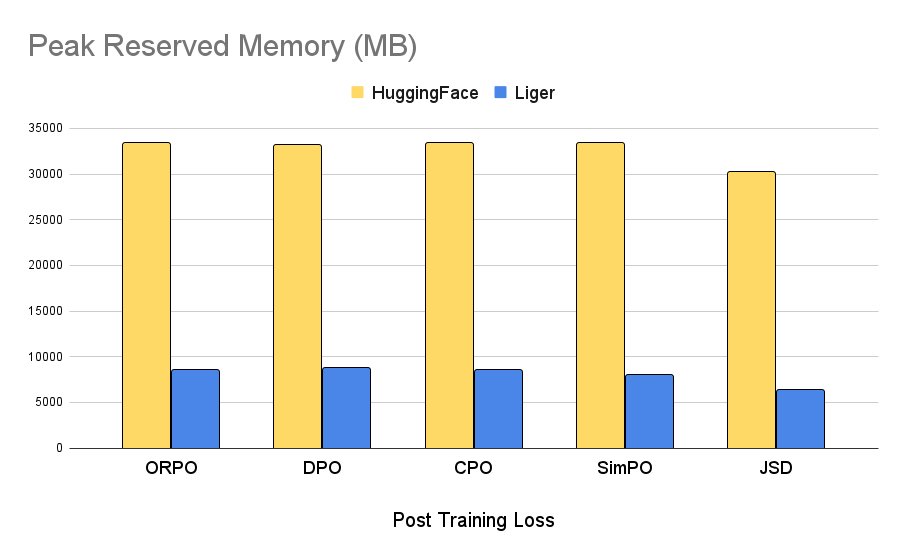
It's interesting that this "kernel" is designed for torch.compile(), so it's Python code but turns out faster! Conversely, some of the other Liger kernels are Triton and I measured them as slower than torch.compile'd versions.
Torch.compile() Outperforms Triton for Kernel Optimization
By
–