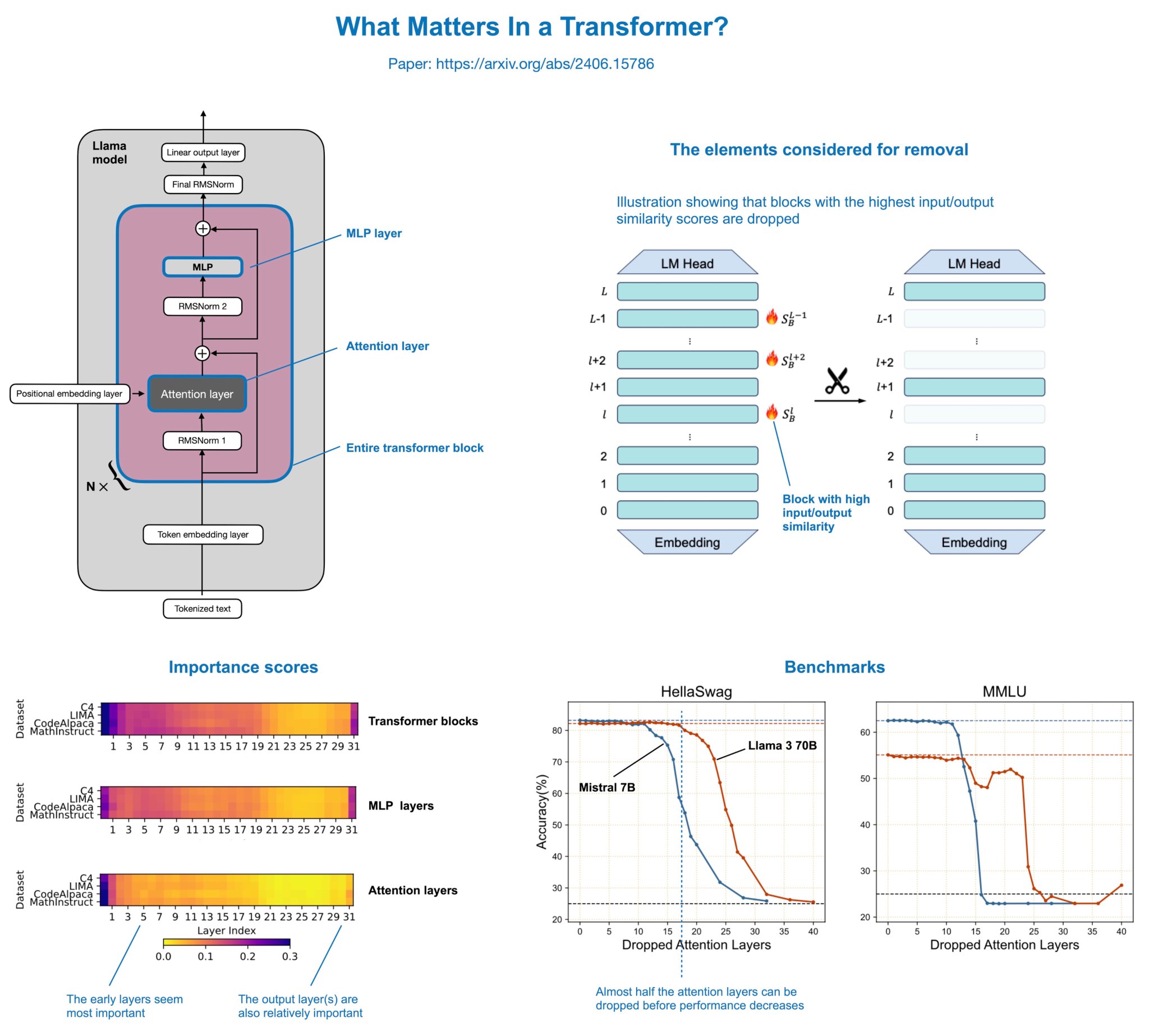
Exploring Redundancy in Transformers: Insights from "What Matters In Transformers?" The paper "What Matters In Transformers?" https://
arxiv.org/abs/2406.15786 presents a fascinating discovery: nearly half of the attention layers in large language models (LLMs) like Llama can be
Transformer Redundancy: Half of Attention Layers Expendable
By
–