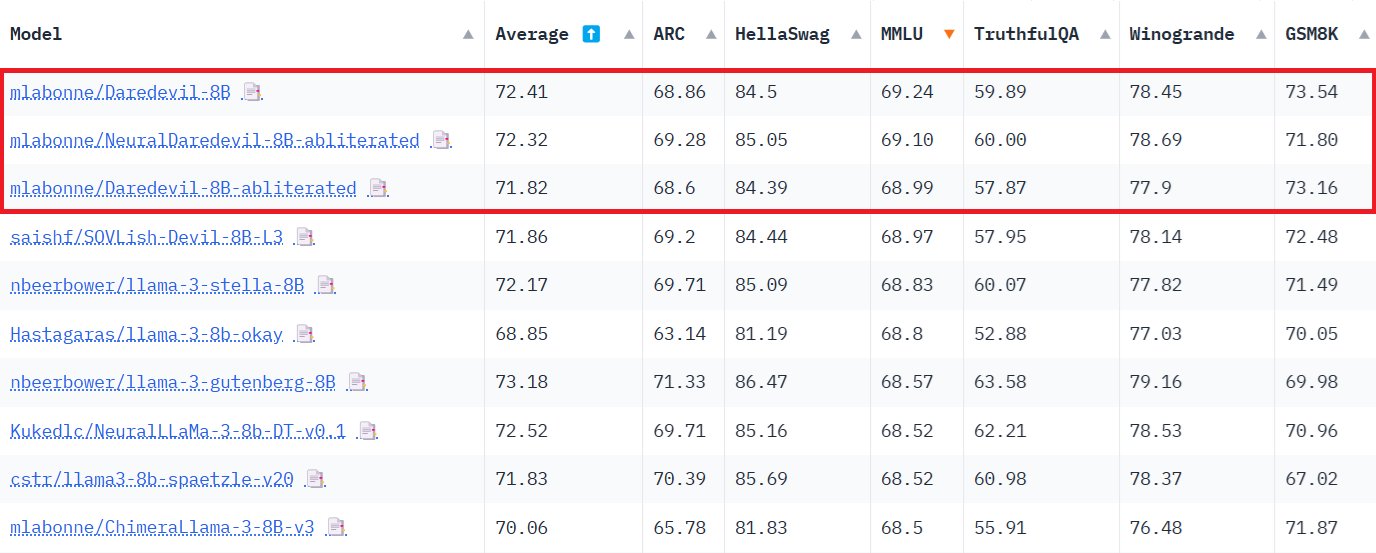
I healed it using DPO fine-tuning. Unlike SFT, it doesn't lobotomize the Instruct model. I trained it for one epoch of orpo-dpo-mix-40k with an lr of 5e-6 and a sequence length of 2048 using Axolotl. This successfully fixed the model as you can see on the benchmarks.
DPO Fine-Tuning Fixes Instruct Model Performance Effectively
By
–