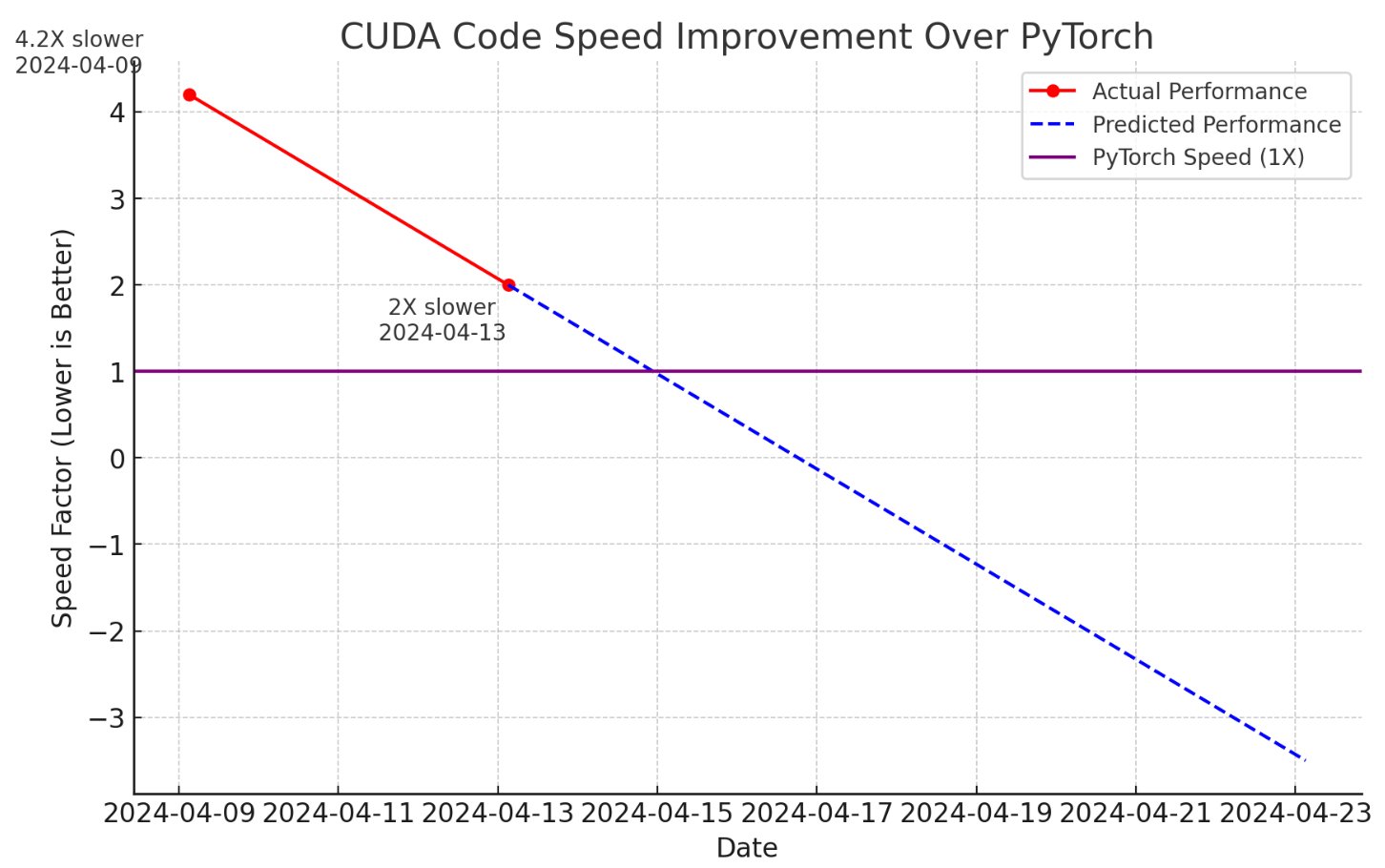
A few new CUDA hacker friends joined the effort and now llm.c is only 2X slower than PyTorch (fp32, forward pass) compared to 4 days ago, when it was at 4.2X slower The biggest improvements were:
– turn on TF32 (NVIDIA TensorFLoat-32) instead of FP32 for matmuls. This is a
llm.c Performance Optimization: Closing Gap with PyTorch
By
–