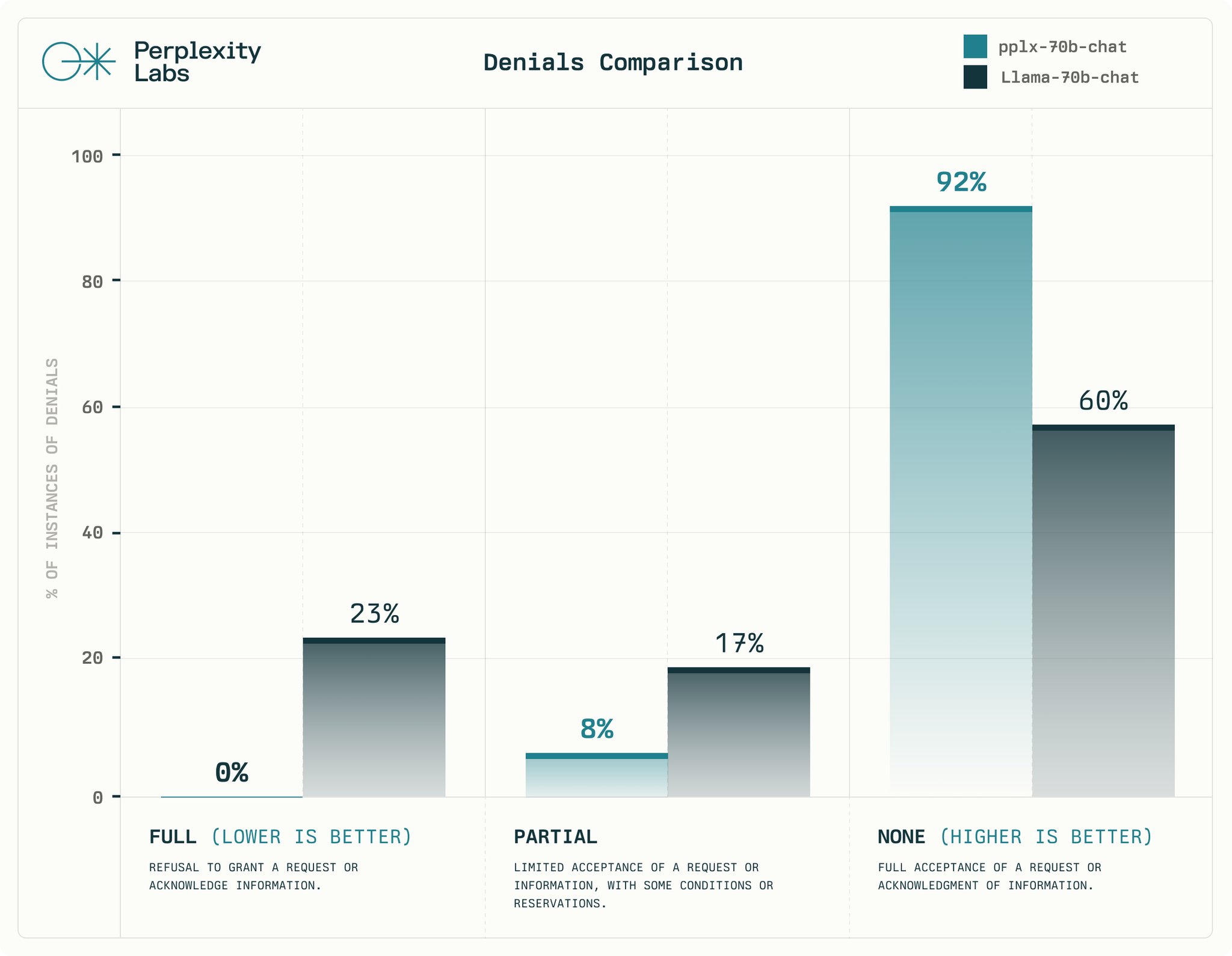
Our models prioritize intelligence, usefulness, and versatility on an array of tasks, without imposing moral judgments or limitations. Comparing pplx-70b-chat and llama-2-70b-chat (by @AIatMeta ), human evaluators saw: 22.7% fewer “full denials” and 31.9% more “no denials”