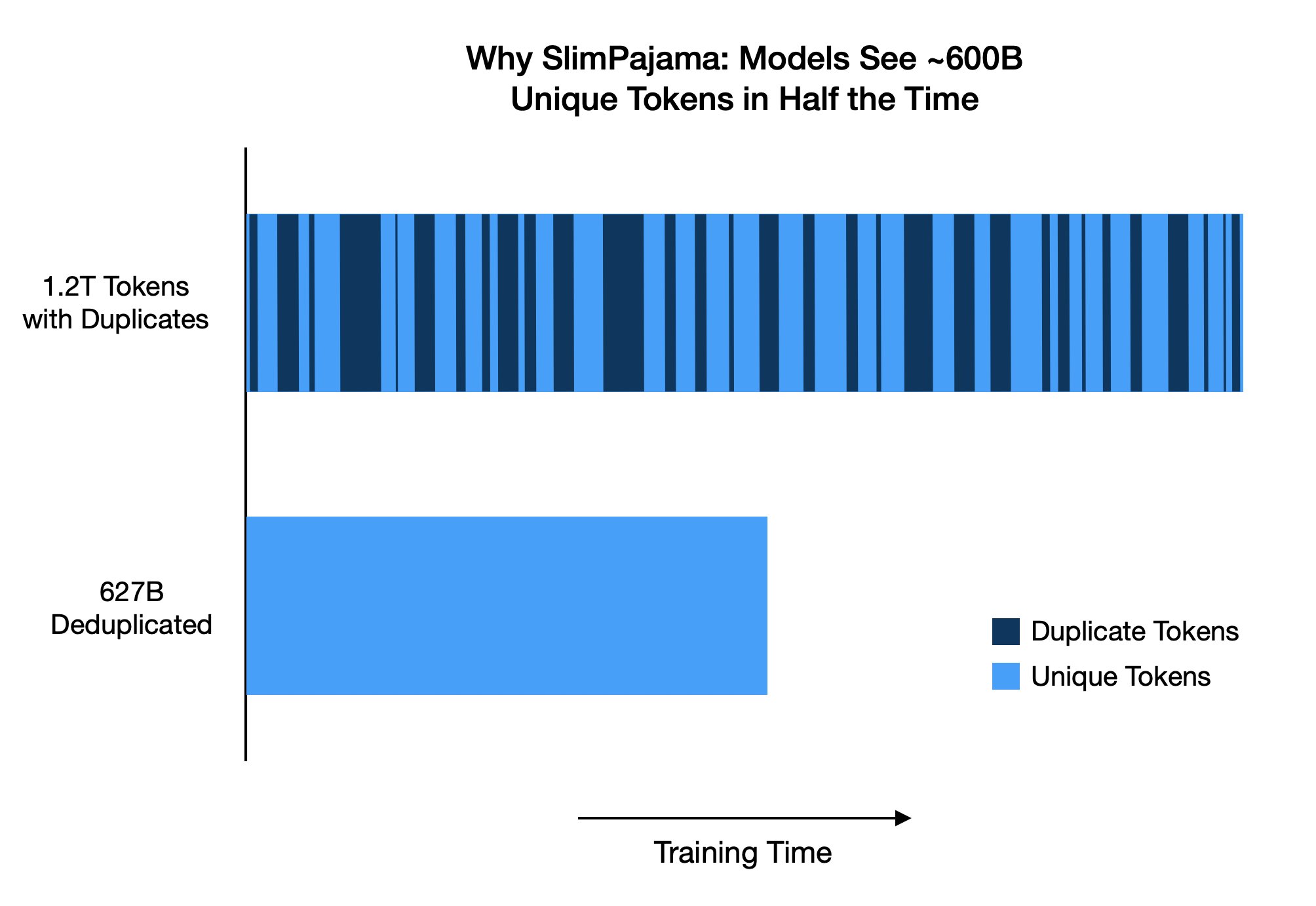
Why we built SlimPajama – it's all about training efficiency. Without de-duplication, a model would have to go through 1.2T tokens before seeing ~600B unique tokens. SlimPajama sees 600B tokens in half the time. That saves you 50% on compute costs! https://
cerebras.net/blog/slimpajam
a-a-627b-token-cleaned-and-deduplicated-version-of-redpajama
…
SlimPajama Reduces AI Training Compute Costs by 50 Percent
By
–