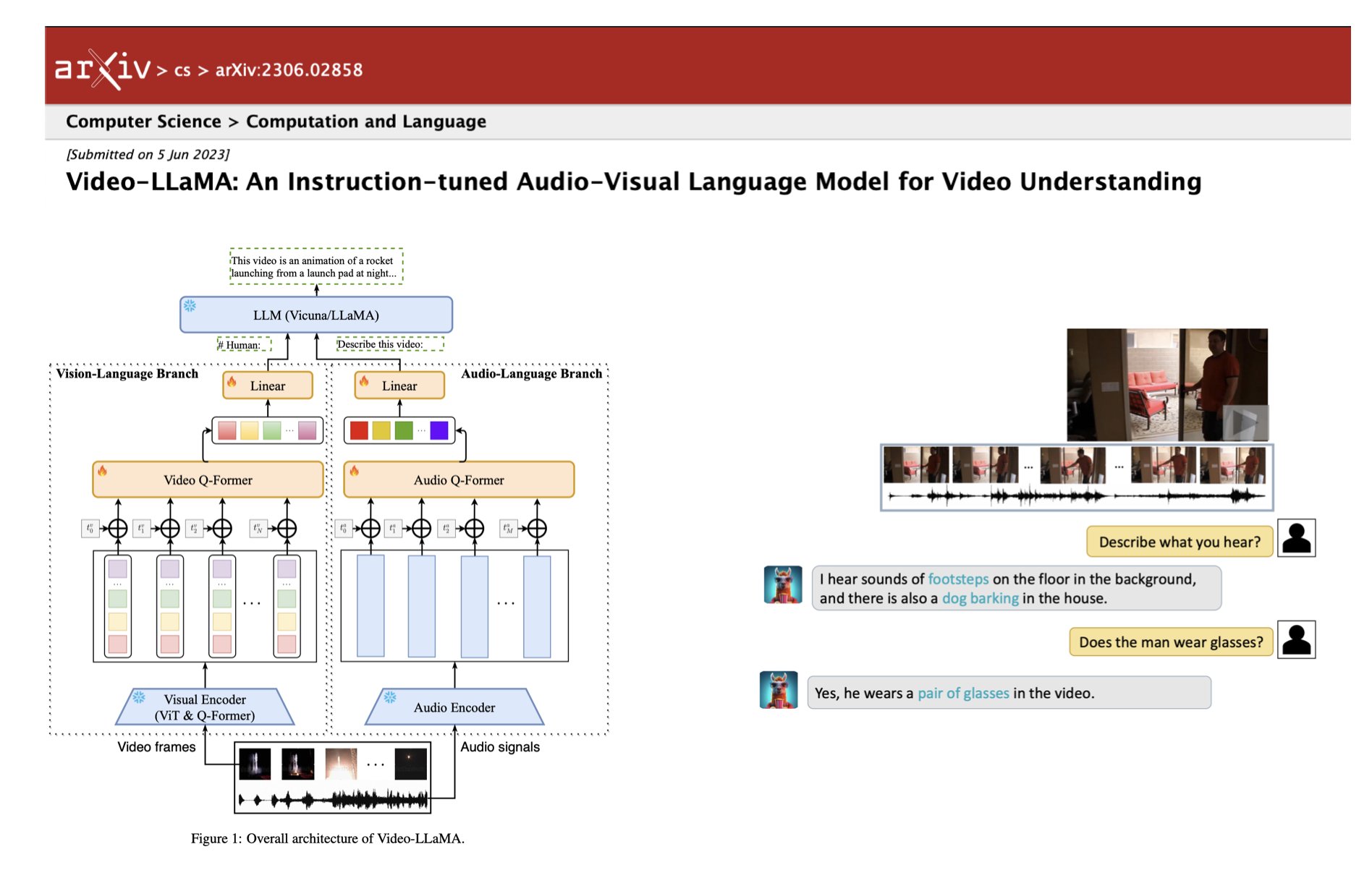
"Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Understanding". This method is pretty cool, but what is this new trend where papers don't contain any type of quantitative model evaluation? Looks like researchers are in a rush. https://
arxiv.org/abs/2306.02858
Video-LLaMA Paper Lacks Quantitative Evaluation Metrics
By
–