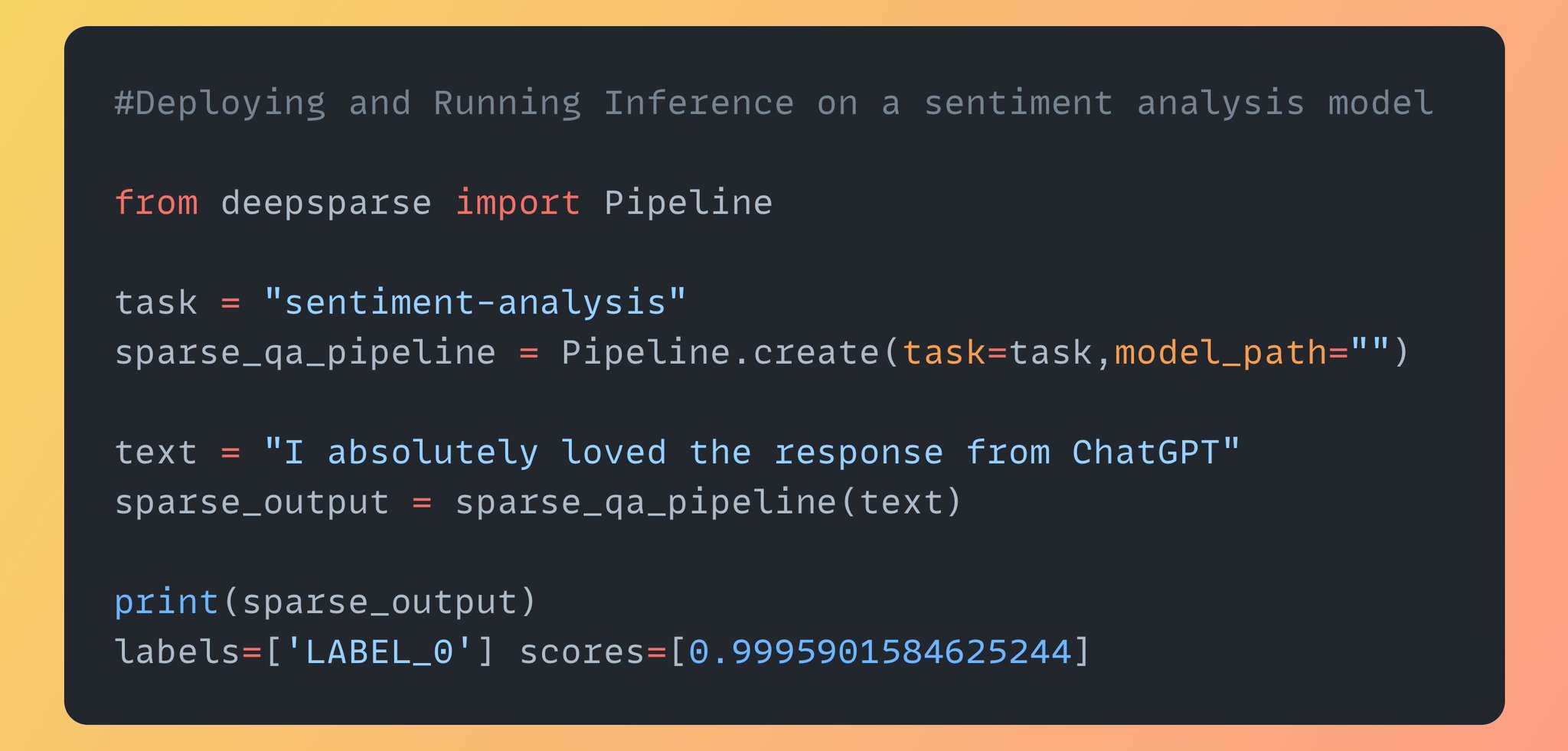
Latency is critical when deploying machine learning models for real-time inference But running large models at low latency requires expensive hardware. DeepSparse enables the deployment of large models with GPU-class performance on CPUs Here is how DeepSparse does it:
DeepSparse: GPU-Class ML Inference Performance on CPUs
By
–