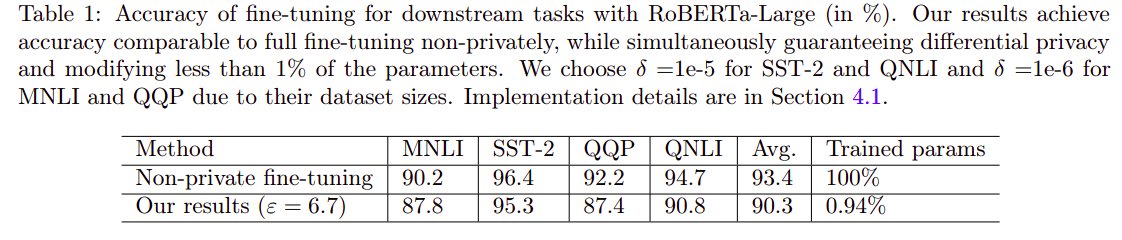
Story is similar for language models. In some prior works at #ICLR2022 (by Yu et al https://
arxiv.org/abs/2110.06500 and @lxuechen et al https://
arxiv.org/abs/2110.05679), it was shown that privately fine-tuning (publicly) pretrained LLMs suffers only a modest utility loss. 4/n
Private Fine-Tuning of LLMs Shows Modest Utility Loss
By
–