I think Anthropic needs to build a certification department that audits and approves users of powerful models. Computer security companies, biotech researchers, academic labs, doctors, government institutions need access to the best AI we can build.
CYBERSECURITY
-

How to Build an AI Governance Framework for Identity
By
–
How to Build an #AI Governance Framework for Identity
by Dustin Sachs @SCMagazine Learn more: https://
bit.ly/4frcLkC #AIAgents #CyberSecurity #InfoSec #IT #Tech #Technology -

AI-powered computer worm poses major cybersecurity threat
By
–
A new #AI-powered computer worm could prove to be the stuff of #CyberSecurity nightmares
by Sharon Goldman @fortunemagazine Learn more: https://
bit.ly/4obzJ1o #InfoSec #IT #Tech #Technology -
DARPA AI Cyber Challenge: multi-agent LLM discovers zero-day vulnerabilities
By
–
At the DARPA AI Cyber Challenge, Team Atlanta from Georgia Institute of Technology demonstrated a multi-agent LLM framework that discovered zero-day vulnerabilities in large codebases and automatically generated, tested, and deployed functional patches without human intervention.… pic.twitter.com/gBxsiw7Jgl
— Lucian Fogoros (@fogoros) 11 juin 2026At the DARPA AI Cyber Challenge, Team Atlanta from Georgia Institute of Technology demonstrated a multi-agent LLM framework that discovered zero-day vulnerabilities in large codebases and automatically generated, tested, and deployed functional patches without human intervention.
-
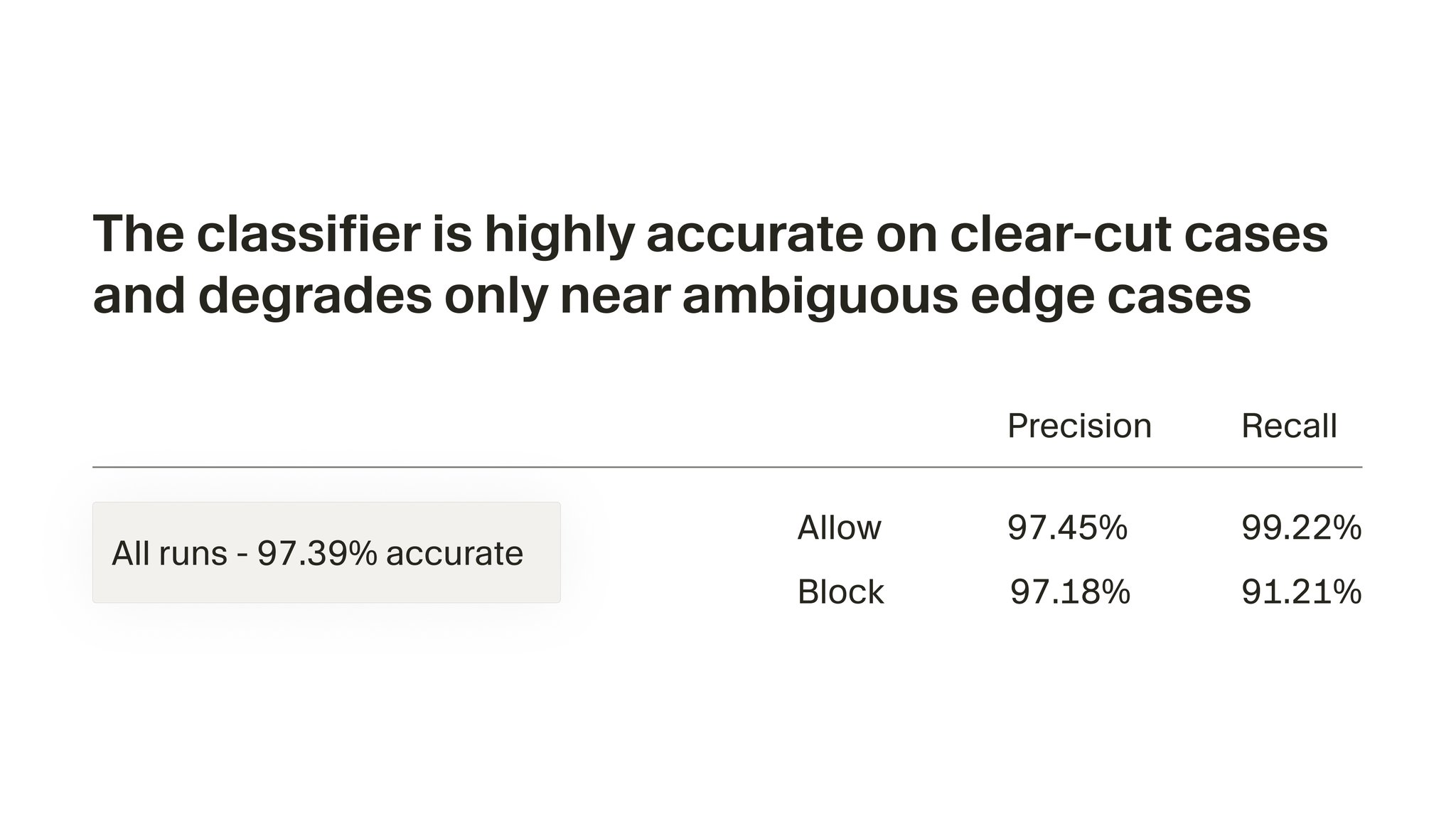
Auto-review becomes default for new users with 97% accuracy
By
–
Auto-review is now the default for all new users. A classifier subagent reviews actions in context before deciding whether to allow, block, or ask for approval. Our evals show it's 97% accurate, with most misses near ambiguous edges.
-
AI improves fake news detection 21%, but feeling smarter is a trap
By
–
2/ With the AI, people got 21% better at catching fake news. The chatbot worked. In the moment, it was a sharp lie detector. Everyone felt smarter. That feeling is the trap.
-
MIT Study: AI Destroys Our Ability to Discern Reality
By
–
URGENT: A new MIT study has revealed that AI is destroying one of your most important skills. Discerning what is real. Here's what they found and how to stop it:
-
Context-aware AI and adaptive governance for data integrity
By
–
Enforcing data integrity at every layer requires a shift towards context-aware AI pipelines. The real evolution is in developing adaptive governance mechanisms that adjust to dynamic threats. As AI scales, proactive security orchestration becomes crucial for sustained trust.
-
Shift from Isolated Security to Holistic AI Governance Frameworks
By
–
The shift we're seeing is from isolated security measures to holistic governance frameworks. The real question isn't just ownership, but how to implement a unified strategy for AI security that integrates across all teams. Effective orchestration will be key to maintaining
-
Visible cyber/bio refusals vs invisible frontier LLM refusals
By
–
Those were the visible refusals for cyber/bio/etc – it was just the refusals for "frontier LLM development" that were deliberately made invisible