Some of mine are
– No Priors
– Vanishing Gradients
– Latent space
– MLOps community
@sudalairajkumar
-
Machine Learning Fundamentals: Priors, Gradients, Latent Space
By
–
-

Three Levels of LLM Evaluation Systems for AI Products
By
–
An insightful blog by @HamelHusain on "Your AI Product Needs Evals" – a must-read for anyone looking to construct robust LLM evaluation systems for their applications. Here are the three levels of creating LLM evaluation systems: ✨ Level 1 – Unit Tests: ▪ Write scoped tests like assertion, regex confirmation, etc. ▪ Create test cases (manually or using LLMs). ▪ Run and track tests regularly whenever there is a change in the system. ✨ Level 2 – Human & Model Evaluation: ▪ Log the traces of the LLM and the system. ▪ Manually review traces to check for failures and improvements. ▪ Utilize LLMs as evaluators. ✨ Level 3 – A/B Testing: ▪ Conduct A/B testing of the LLM system against the current baseline system. Dive into the blog for a deeper understanding – hamel.dev/blog/posts/evals/
→ View original post on X — @sudalairajkumar, 2024-06-14 06:44 UTC
-

Reproducing GPT-2 124M: Comprehensive 4-Hour Video Lecture
By
–
📽️ New 4 hour (lol) video lecture on YouTube: "Let’s reproduce GPT-2 (124M)" piped.video/l8pRSuU81PU The video ended up so long because it is… comprehensive: we start with empty file and end up with a GPT-2 (124M) model: – first we build the GPT-2 network – then we optimize it to train very fast – then we set up the training run optimization and hyperparameters by referencing GPT-2 and GPT-3 papers – then we bring up model evaluation, and – then cross our fingers and go to sleep. In the morning we look through the results and enjoy amusing model generations. Our "overnight" run even gets very close to the GPT-3 (124M) model. This video builds on the Zero To Hero series and at times references previous videos. You could also see this video as building my nanoGPT repo, which by the end is about 90% similar. Github. The associated GitHub repo contains the full commit history so you can step through all of the code changes in the video, step by step. github.com/karpathy/build-na… Chapters. On a high level Section 1 is building up the network, a lot of this might be review. Section 2 is making the training fast. Section 3 is setting up the run. Section 4 is the results. In more detail: 00:00:00 intro: Let’s reproduce GPT-2 (124M) 00:03:39 exploring the GPT-2 (124M) OpenAI checkpoint 00:13:47 SECTION 1: implementing the GPT-2 nn.Module 00:28:08 loading the huggingface/GPT-2 parameters 00:31:00 implementing the forward pass to get logits 00:33:31 sampling init, prefix tokens, tokenization 00:37:02 sampling loop 00:41:47 sample, auto-detect the device 00:45:50 let’s train: data batches (B,T) → logits (B,T,C) 00:52:53 cross entropy loss 00:56:42 optimization loop: overfit a single batch 01:02:00 data loader lite 01:06:14 parameter sharing wte and lm_head 01:13:47 model initialization: std 0.02, residual init 01:22:18 SECTION 2: Let’s make it fast. GPUs, mixed precision, 1000ms 01:28:14 Tensor Cores, timing the code, TF32 precision, 333ms 01:39:38 float16, gradient scalers, bfloat16, 300ms 01:48:15 torch.compile, Python overhead, kernel fusion, 130ms 02:00:18 flash attention, 96ms 02:06:54 nice/ugly numbers. vocab size 50257 → 50304, 93ms 02:14:55 SECTION 3: hyperpamaters, AdamW, gradient clipping 02:21:06 learning rate scheduler: warmup + cosine decay 02:26:21 batch size schedule, weight decay, FusedAdamW, 90ms 02:34:09 gradient accumulation 02:46:52 distributed data parallel (DDP) 03:10:21 datasets used in GPT-2, GPT-3, FineWeb (EDU) 03:23:10 validation data split, validation loss, sampling revive 03:28:23 evaluation: HellaSwag, starting the run 03:43:05 SECTION 4: results in the morning! GPT-2, GPT-3 repro 03:56:21 shoutout to llm.c, equivalent but faster code in raw C/CUDA 03:59:39 summary, phew, build-nanogpt github repo
→ View original post on X — @sudalairajkumar, 2024-06-09 23:41 UTC
-
Jarvislabs: Bootstrapped Indian GPU Company’s Journey and Vision
By
–
Ola recently announced that they are bringing affordable AI to Indian developers.
— Vishnu – Jarvislabs.ai (@vishnuvig) 9 mai 2024
𝐉𝐚𝐫𝐯𝐢𝐬𝐥𝐚𝐛𝐬 an Indian company has been providing affordable GPUs for developers across the globe since 2020. We are a little known, so I want to share our story here.
𝐖𝐡𝐨 𝐰𝐞 𝐚𝐫𝐞… pic.twitter.com/0M0YfFABHyOla recently announced that they are bringing affordable AI to Indian developers. 𝐉𝐚𝐫𝐯𝐢𝐬𝐥𝐚𝐛𝐬 an Indian company has been providing affordable GPUs for developers across the globe since 2020. We are a little known, so I want to share our story here. 𝐖𝐡𝐨 𝐰𝐞 𝐚𝐫𝐞 We are bootstrapped, building from the outskirts of Coimbatore. Started as a small team of 4, from humble backgrounds none from IITs/IIMs. Currently, we are a team of 12+. 𝐖𝐡𝐚𝐭 𝐰𝐞 𝐚𝐜𝐡𝐢𝐞𝐯𝐞𝐝 The cost of hosting GPU servers 4 years back in India was insanely high. We got 2 quotes which charged us Rs. 1.5L for a single server per month. At that cost, it was not practical for us to do the business. So we went to the first principle to build an MVP for a mini data center/server room. For the first few years, we ran all our servers from a room fitted with ACs, a UPS, and a Generator, which experts claimed would not work. As we scaled, we faced the heat of our setup, but by then we accumulated more money than we had. So last year we moved it to a tier 3+ DC near Bangalore. This helped us boost the confidence of our users, as we have redundancy for power, internet, and networking which gives us and our customers a lot of peaceful nights. 𝐖𝐡𝐨 𝐮𝐬𝐞𝐬 𝐉𝐚𝐫𝐯𝐢𝐬𝐥𝐚𝐛𝐬 Developers and artists from across the world have supported us in our journey. Some prominent companies are ZOHO (My inspiration), Weights and Biases, UNC, UpGrad, and many more. 𝐑𝐞𝐯𝐞𝐧𝐮𝐞 We crossed 580K USD in the last financial year, the highest ever in our history. Being bootstrapped, the only way for us to grow is to put all the money back. Our customers are our investors, as a founder I have hardly taken a paycheck for the last 4+ years, since the team also believes in our vision they are happy not taking a fancy cheque. 𝐕𝐢𝐬𝐢𝐨𝐧 As AI evolves, we want to bring the capabilities of AI to users at the lowest prices possible. Being bootstrapped, the only way to survive is to be frugal and disciplined. 𝐇𝐢𝐫𝐢𝐧𝐠 I am proud of our hiring strategy. We hired only freshers to date, and most of our hires do not have a formal degree. They come from rural areas and economically challenged backgrounds. The average age of our new team is 19. They have played an active role in building our V2 of Jarvislabs and improving the product daily. I love to thank everyone for supporting us in our journey. Thanks to Analytics India Magazine, INDIAai, fastai for recognizing us in our early years. If our story resonates with you, Please share our story to inspire others & support our mission. #StartupIndia
→ View original post on X — @sudalairajkumar, 2024-05-09 11:09 UTC
-
Metaforms AI: OpenAI meets Typeform innovation
By
–
Yes, Typeform is shit expensive, but that's because they've not upgraded at all.
— Akshat Metaforms (@ofcAkshat) 4 avril 2024
It's exactly the same single-scree interface that it was 10 years ago.
Imagine if OpenAI and Typeform had a kid— Introducing Metaforms AI pic.twitter.com/wa2D4eWEElYes, Typeform is shit expensive, but that's because they've not upgraded at all. It's exactly the same single-scree interface that it was 10 years ago. Imagine if OpenAI and Typeform had a kid— Introducing Metaforms AI
→ View original post on X — @sudalairajkumar, 2024-04-04 09:07 UTC
-
3Blue1Brown’s Visual Guide to GPT and Transformers
By
–
In case you missed it, 3Blue1Brown has released a video on "But what is a GPT?Visual intro to Transformers" couple of days back. Even if you have a good knowledge on Transformers, this is highly recommended. Visual illustrations help us grasp the underlying concepts easily. Link: piped.video/watch?v=wjZofJX0… Looking forward to the next two videos of the series. Happy learning!
→ View original post on X — @sudalairajkumar, 2024-04-04 04:51 UTC
-

RAG in 2024: Retrievers, Agents, and Latest Research Insights
By
–
🌟 RAG in 2024 with @llama_index Super excited to share that I will be speaking about RAG in 2024 with @llama_index at @SaamaOfficial Connect March Meetup in Chennai this Saturday. I will be covering a wide range of topics: 1️⃣ Retrievers 2️⃣ Agents 3️⃣ Latest Research in RAG 4️⃣ Why RAG is still relevant with the emergence of Long Context LLMs. 👥 Meetup Details : Saama Connect March Meetup – NLP Deep Dive 2024 📅 30th Mar 2024 (Saturday), 10:00 AM to 01:00 PM IST 📌 Register here – shorturl.at/rFUW0
→ View original post on X — @sudalairajkumar, 2024-03-26 04:40 UTC
-

Opportunity to work on ML at Raven Mail
By
–
A great opportunity to work with @DudeWhoCode on the ML side of things @ravenmailinc ! naren.io (@nareni0) Hiring alert 🚨 At @ravenmailinc we are early, remote first, engineering centric hackers, we think bigger and iterate smaller. Here are some thoughts on what we do and how we work at Ravenmail. 👉ravenmail.notion.site/Career… If this resonates w/ you, DM me. Others RT for coffee. — https://nitter.net/nareni0/status/1766742432786350532#m
→ View original post on X — @sudalairajkumar, 2024-03-10 09:16 UTC
-

Navarasa: Gemma 7B/2B Instruction-Tuned Model for 9 Indian Languages
By
–
🔥 𝐑𝐞𝐥𝐞𝐚𝐬𝐢𝐧𝐠 𝐈𝐧𝐝𝐢𝐜 𝐆𝐞𝐦𝐦𝐚 7𝐁/2𝐁 𝐈𝐧𝐬𝐭𝐫𝐮𝐜𝐭𝐢𝐨𝐧 𝐭𝐮𝐧𝐞𝐝 𝐦𝐨𝐝𝐞𝐥 𝐨𝐧 9 𝐈𝐧𝐝𝐢𝐚𝐧 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞𝐬 — 𝐍𝐚𝐯𝐚𝐫𝐚𝐬𝐚 🚀 We are thrilled to share 🌟 𝐍𝐚𝐯𝐚𝐫𝐚𝐬𝐚, a Gemma 7B & 2B instruction-tuned models in 9 Indian Languages – Perhaps this is the first Indic open instruction-tuned model trained in 9 Indian languages additionally English included. 🔥𝐍𝐚𝐯𝐚𝐫𝐚𝐬𝐚 is a Gemma 7B & 2B SFT model using Gemma 7B & 2B base models. Last week we released the Telugu Gemma 7B/ 2B SFT model using curated Telugu datasets from Telugu LLM Labs and we observed really good performance compared to Llama2-based models. 🌐 So, we thought why don’t we scale up Gemma 7B & 2B models to multiple Indian languages and we went ahead with testing tokenizers of the following 9 Indian Languages and English Language. 1. Hindi 2. Telugu 3. Tamil 4. Malayalam 5. Kannada 6. Gujarati 7. Bengali 8. Punjabi 9. Odia 10. English ✨ We found the model to have the following capabilities: (X represents any other Indian language) 1. Instruction and Input in Native X language, Output in Native X language. 2. Instruction and Input in English language prompted to respond in Native X language, Output in Native X language. 3. Instruction in Native X language, Input in English language, and Output in Native X language. 📊𝐓𝐫𝐚𝐢𝐧𝐢𝐧𝐠 𝐃𝐞𝐭𝐚𝐢𝐥𝐬: 1. Single A100 machine which took approx. 36 hours for the 7B model and 15 hours for the 2B model. 2. Platform: E2E Networks Limited 📝 We have shared details on datasets, Examples of Reasoning, Translation, and Question Answering with Context in our blog post. 🤝 The work would not have been possible without huge community effort from different languages and a huge shout out to each one of their work over the past few months showcasing the true OSS power. Following are details of contributors for the languages: 1. Hindi: @SarvamAI 2. Telugu: Telugu LLM Labs 3. Tamil: @abhinand58 4. Kannada: @adarshxs and the team at Tensonic 5. Malayalam: Vishnu Prasad J 6. Odia: @OdiaGenAI 7. Gujarati: Adarsh Shirawalmath and the team at Tensonic 8. Punjabi: HydraIndicLM 9. Bengali: HydraIndicLM 👏 Special thanks to @unslothai for simplifying the training and inference processes! 🔜 As we release these models, the next step is to create romanized datasets and we are working hard on evaluation datasets so that we can benchmark and improve on top of it. 🤝 This work is done in collaboration with @ramsri_goutham as part of the Telugu LLM Labs independent initiative. 𝐁𝐥𝐨𝐠𝐏𝐨𝐬𝐭: shorturl.at/jBQWY 𝐂𝐨𝐝𝐞𝐁𝐚𝐬𝐞: shorturl.at/elxBF
→ View original post on X — @sudalairajkumar, 2024-03-06 05:14 UTC
-
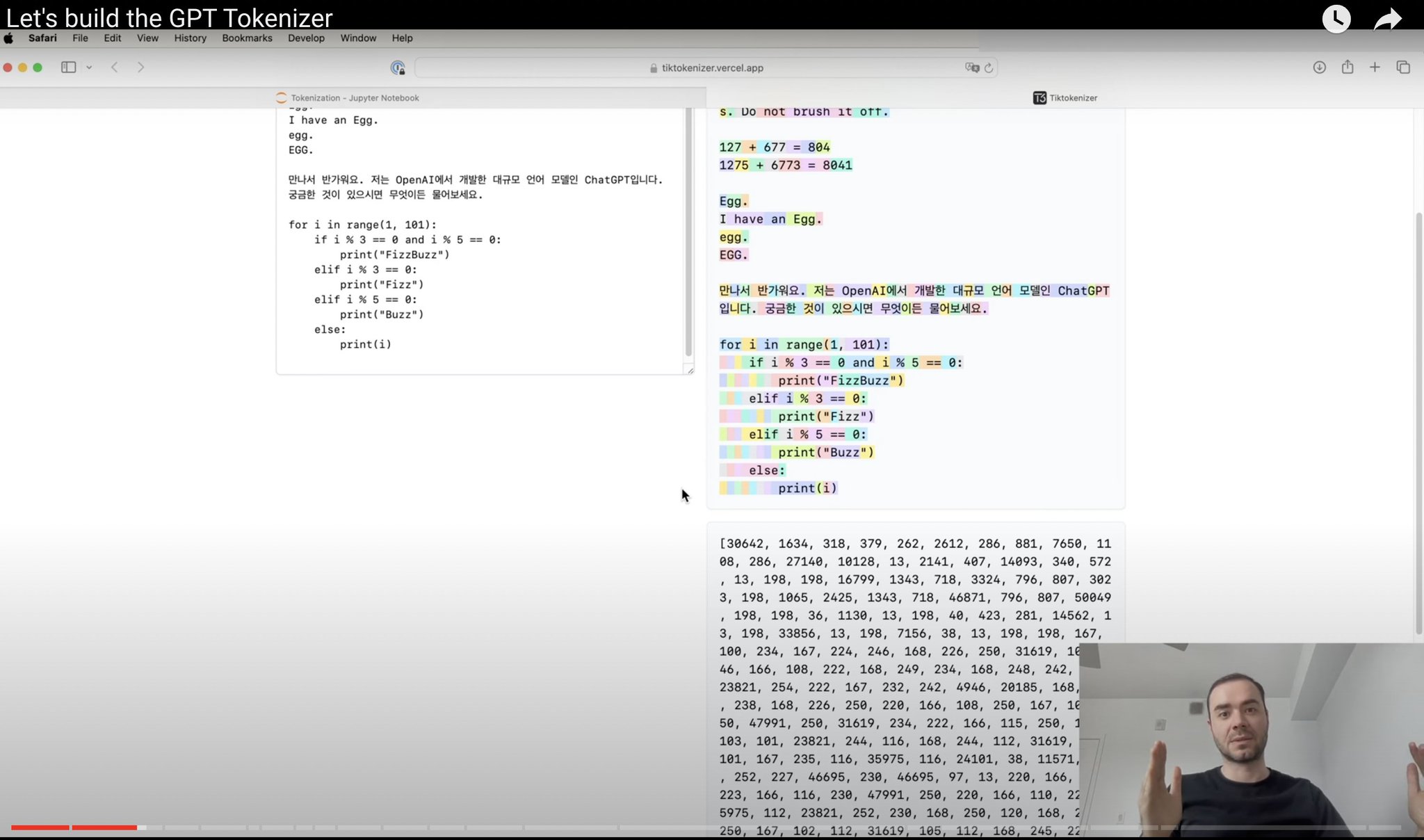
Karpathy releases tokenization tutorial covering UTF-8 and byte pair encoding
By
–
ICYMI – Andrej Karpathy has released an excellent video tutorial on "Tokenization" couple of days back. ⦿ Basics covered: Strings, Unicode code points, and encodings like UTF-8.
⦿ Byte pair encoding algorithm explained and implemented in Python.
⦿ Delving into complexities: