Since there will be 30000 top conference papers every year, and surely you will not read/cite most of your even directly related paper, time to think about what will be real impact (especially for industrial researchers)
@shiqi_yang_147
-
Visual Generation Expert Wanted: Top Conference Publication Required
By
–
The candidate should have experience on visual generation OR audio-visual related topics, ideally with experience with 1st authored top conference paper
-
Audio-visual generation internship opportunity in Japan
By
–
Looking for 1 intern on audio-visual generation (potentially video2audio generation)! We have the largest computation resources in Japan, and we do serious industrial research (and development). DM if interested, and you can find more about me in my homepage.
-

Submit Extended Conference Papers to IJCV Special Issue
By
–
Consider submitting to our IJCV special issue, extended submissions from conference papers are welcome (typically ≥30% new content)
-

InterLCM: Fast Diffusion Model for Image Generation
By
–
Project page: https://
sen-mao.github.io/InterLCM-Page/ -
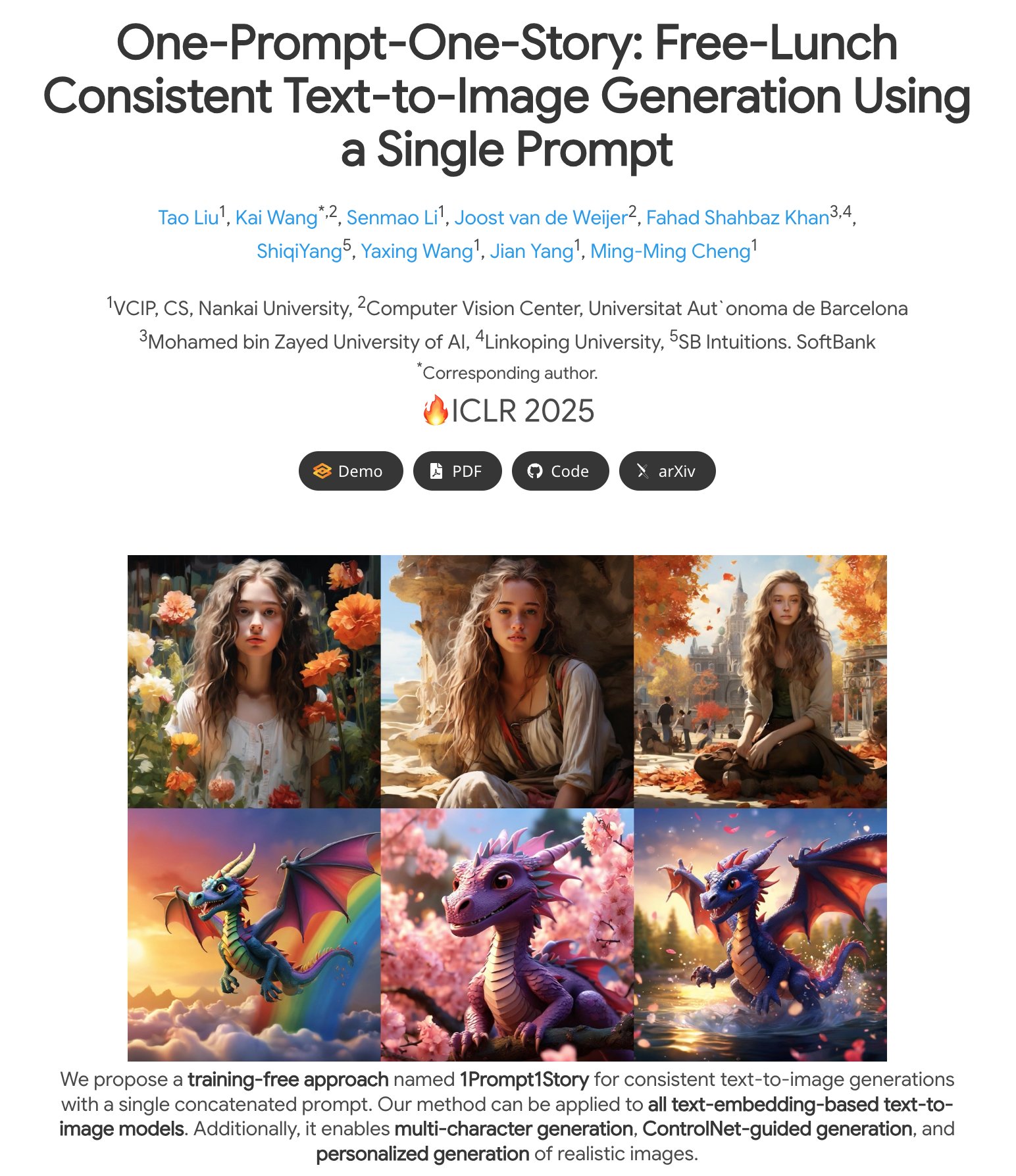
1Prompt1Story: Creative AI Generation from Single Prompts
By
–
Project page: https://
byliutao.github.io/1Prompt1Story.
github.io/
… -
AI Model Safety and Regulation Surge in Recent Discussions
By
–
Only around these days I am seeing huge amounts of posts talking about AI model safety/regulation, lmao
-
Incentives for industrial AI researchers and team motivation
By
–
What should be the good incentives for industrial researchers Maybe the motivations of people in the same team vary
-
Essential Skills for Modern Multimodal AI Projects
By
–
Surely, the ability to inspire/motivate others is also a very important merit, as well as adaptability to unexpected and unknown thing. I guess all these will also be appreciated in big multimodal and multitask AI projects nowadays
-
Great Leadership in Science: Oppenheimer’s Vision and Team Building
By
–
My deepest impression of the movie "Oppenheimer", is that it actually shows what does a good (great) leader look like. Self as an excellent scientist, which is the base to attract/convince other talented people, clear strategic vision and interdisciplinary communication.