Hey hey, this update just unifies all the limits that have existed on the hub for a long while. For example for datasets we’ve been granting storage (similar to GPU grants) for awhile now (ref below) We’ll continue to grant storage + GPUs as has been. The grants don’t reflect on
@reach_vb
-
Sharing query results in discussions: feature enhancement
By
–
Thanks for the feedback, currently we allow users to share the query + the results via the share option (and then you can even embed it) but, maybe sharing results somewhere in discussions might be much more interesting. cc: @calebfahlgren @julien_c as well on this
-
Try llms-txt: New Tool for Language Models
By
–
You should try it on `llms-txt`: Would love to hear feedback!
-
AI-Powered SQL Query Tool Launch on Hugging Face
By
–
try it out today on http://
hf.co/datasets – just click on `SQL Console` followed by `AI Query` -
Execute SQL Queries with AI in Your Browser Today
By
–
you can just do things – ask AI to create your SQL queries and execute them right in your browser! 🔥
— Vaibhav (VB) Srivastav (@reach_vb) 2 décembre 2024
let your creativity guide you – powered by @Alibaba_Qwen 2.5 coder 32b ⚡
available on all 254,746 public datasets on the hub!
go check it out today! 🤗 pic.twitter.com/YYIiNaSFJKyou can just do things – ask AI to create your SQL queries and execute them right in your browser! let your creativity guide you – powered by @Alibaba_Qwen 2.5 coder 32b available on all 254,746 public datasets on the hub! go check it out today!
-
Web-LLM and WebGPU: Superior Choice for LLMs
By
–
Thanks for covering this Simon, @tqchenml & @charlie_ruan are the real MVPs for developing Web-LLM – for LLMs and WebGPU it is literally the superior choice!
-
Structured JSON Generation with SmolLM2 in Browser
By
–
Fuck it! Structured Generation w/ SmolLM2 running in browser & WebGPU 🔥
— Vaibhav (VB) Srivastav (@reach_vb) 28 novembre 2024
Powered by MLC Web-LLM & XGrammar ⚡
Define a JSON schema, Input free text, get structured data right in your browser – profit!!
To showcase how much you can do with just a 1.7B LLM, you pass free text,… pic.twitter.com/x5GYWdmTe3Fuck it! Structured Generation w/ SmolLM2 running in browser & WebGPU Powered by MLC Web-LLM & XGrammar Define a JSON schema, Input free text, get structured data right in your browser – profit!! To showcase how much you can do with just a 1.7B LLM, you pass free text,
-
Optimizing AWQ Deployment for Flexible Model Distribution
By
–
Think a more likely one would be to help people create the best, most optimised AWQs and then they can deploy wherever they want ofc you can have direct deployment options. But I’m 100% there’s value in this.
-
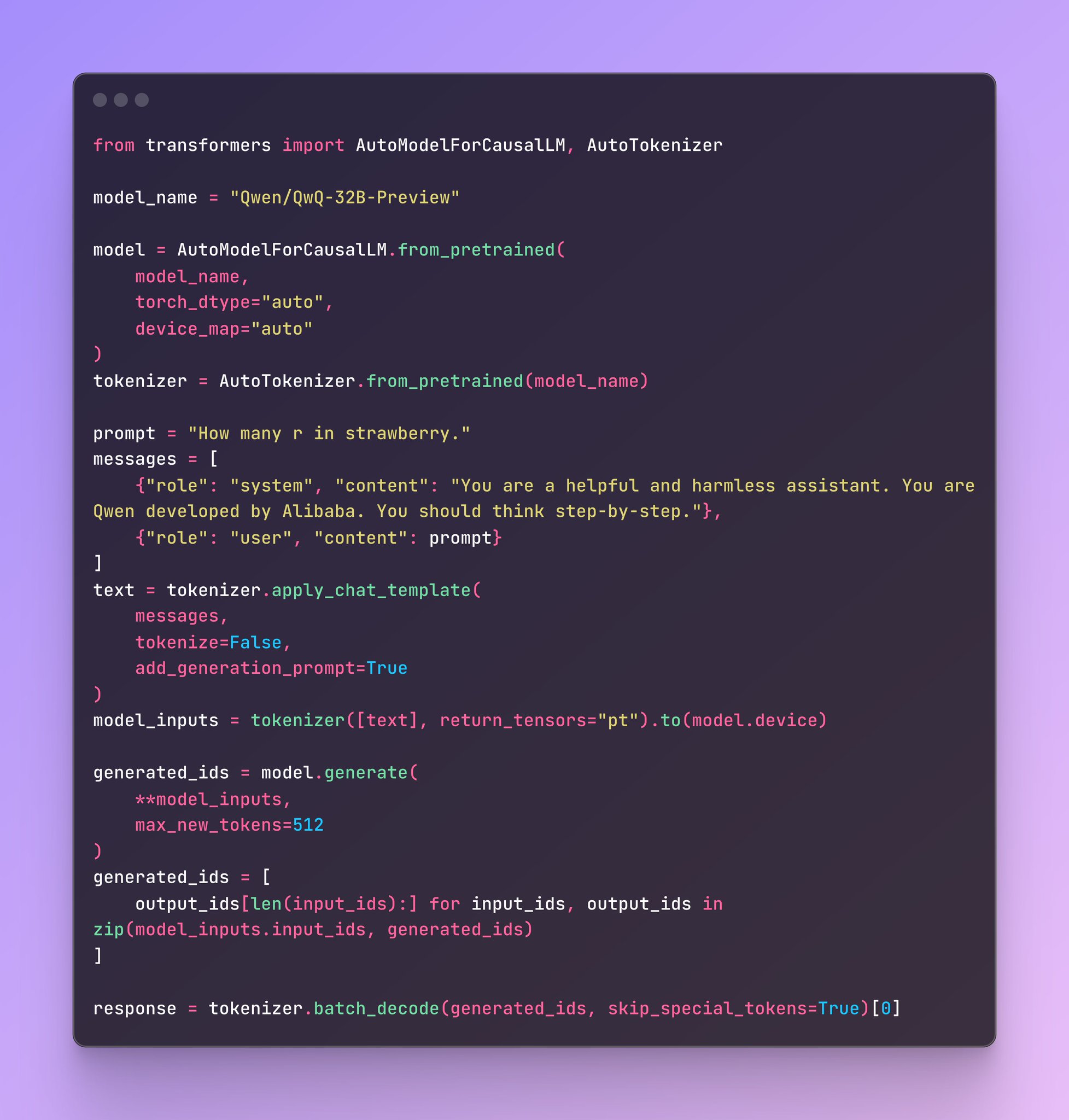
AGI Accessible: Install QwQ with Two Lines of Code
By
–
You too can have AGI in just a couple lines of code! `pip install transformers` & QwQ is all you need
-
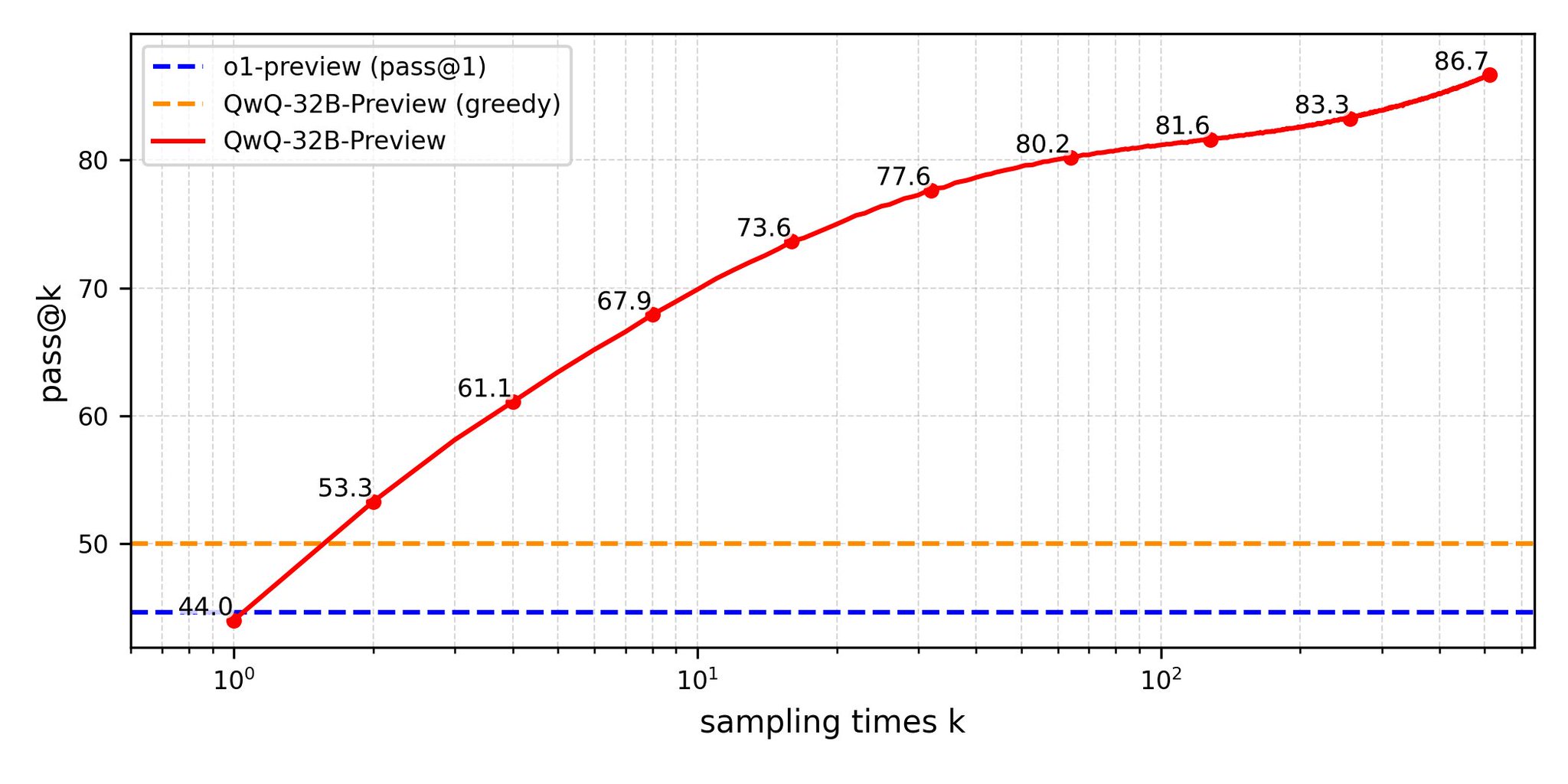
Open Source Model Challenges OpenAI o1 Moat
By
–
That’s an Apache 2.0 licensed model competing with OpenAI o1 preview – the moat never existed!