Come on @gdb @sama , Google and Anthropic are currently thrashing you on this critical metric: UK roles open:
– Anthropic: 21
– DeepMind: 17
– OpenAI: 3
@petergostev
-
Anthropic and DeepMind Lead UK AI Hiring Over OpenAI
By
–
-
Coding Tools Default to Sonnet 4: Homogenization Problem
By
–
I find it problematic that all coding & vibe coding tools default to Sonnet 4, sometimes even without an option to change the model. All vibe-coded apps end up looking the same, encountering the same kind of problems (e.g. 'I see the issue now!'). Similar to AI text slop, you can
-
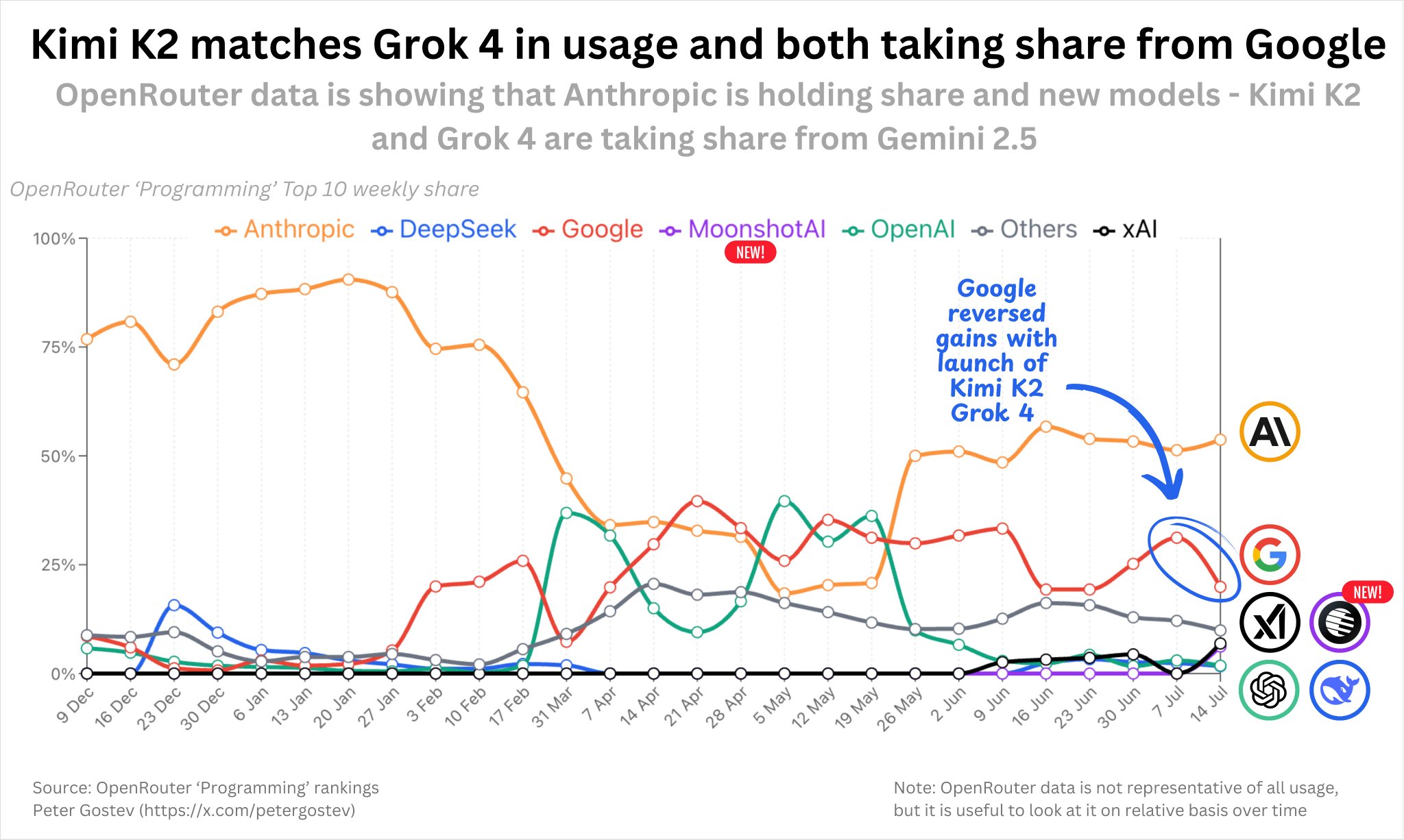
Grok 4 matches Kimi K2 coding performance on OpenRouter
By
–
Grok 4 @xai matches Kimi K2's @Kimi_Moonshot coding share in @openrouter
, taking share from Google. Anthropic's share stays steady. -
Continuous Learning and Personalization in AI Systems
By
–
In principle I agree, but in practice we have a small niche use case and this (taste) data won't make it out into the outside world. There'll be millions of people who have different taste requirements and continuous learning for them would be a massive unlock. Yes we can fine
-
LLMs Lack Continuous Learning for Creative Quality Assessment
By
–
But don't you think that at least some of taste would come from continuous learning? We are working on a creative project now and it is a pain the LLMs are incapable of learning what is good and what is bad, while humans are learning pretty quickly, at least to some base level
-
Replit Agent Builds Apps from Natural Language Prompts
By
–
Can you please go to Replit com, in there you will see the Replit agent on the front page (under Hi Peter, what do you want to make?), where you will need to enter your prompt and click 'Start Chat'. This agent will then spend several minutes building an app for whatever it is
-
OpenAI Agent Collaborates with Replit Agent to Build Game
By
–
Agent + Agent collaboration: today I've asked @OpenAI Agent to build a game using @Replit Agent. The key advantage of the OpenAI Agent is that it can use the UI and test the game, making sure that it is playable and bug free.
— Peter Gostev (@petergostev) 21 juillet 2025
All I did was send a prompt to the Agent, logged… pic.twitter.com/wsxTE6h13uAgent + Agent collaboration: today I've asked @OpenAI Agent to build a game using @Replit Agent. The key advantage of the OpenAI Agent is that it can use the UI and test the game, making sure that it is playable and bug free. All I did was send a prompt to the Agent, logged
-
ChatGPT Operator and Replit Agent Integration for Development
By
–
https://
linkedin.com/posts/peter-go
stev_chatgpt-operator-please-use-replit-agent-activity-7332880005665849344-YtUk
… I actually did this with @Replit and the updated Operator, need to try again with the new agent -
GPU Shortage Limits AI Model Capabilities and Deployment
By
–
It is crazy to me that some still don't see how big our GPU shortage is: – Most context window is <100k – Delayed rollouts of Agents, Codex – Full Sora never released – Veo 3 roll out taking weeks – Claude constant rate limits – Even big clouds default rate limits are
-

Two AI Agents Complete Task Collaboratively in Meme Format
By
–
The meme in question. I was meant to be done in two parts by two agents – almost worked.