75% is of FTE rather than revenue
@petergostev
-

Nvidia’s Lean Workforce Model with Growing R&D Investment
By
–
What is interesting about Nvidia is that while it is ~the most valuable company, with skyrocketing revenue & profit, the number of employees is not climbing that much. In addition, the proportion of employees allocated to R&D is growing a little, from 72% to 75%, which is a good
-

Claude Capacity Constraints Meme Edvard Munch 1896
By
–
"Due to unexpected capacity constraints Claude is unable to respond to your message"
Edvard Munch, 1896 -
Advanced Research Tasks with AI Models and Prompt Engineering
By
–
Bigger research tasks is where I feel the difference for sure. Write a good prompt, give it a much more ambitious task than you'd normally trust any model with and see if it works. It can do great research and pull together really good outputs (e.g. pdfs, code, word docs)
-
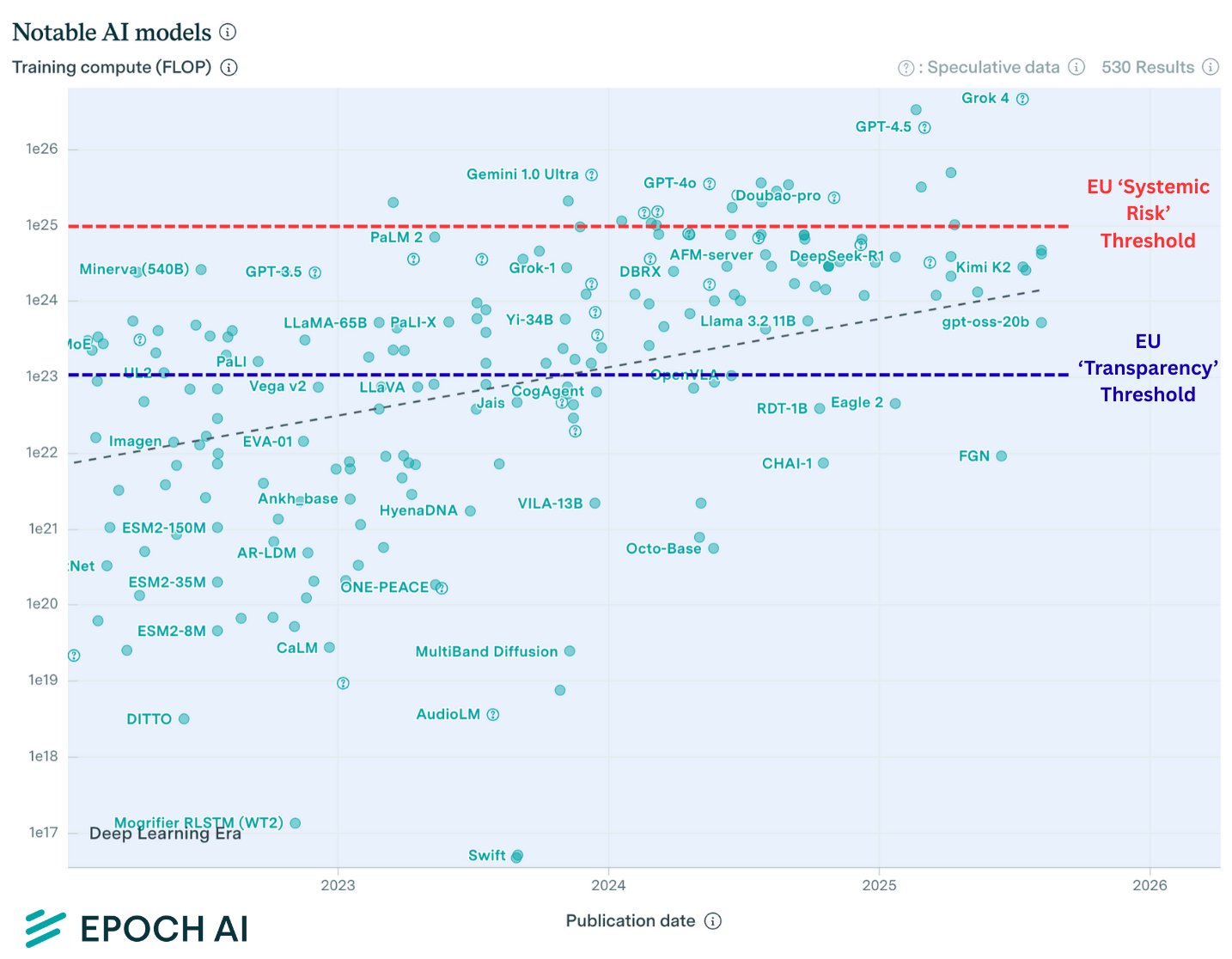
Near-SOTA Models Face Systemic Risk Transparency Requirements
By
–
So basically any near-SOTA model is 'systematically risky', even a 20b OSS model triggers the 'transparency' threshold.
-
Heavy AI Usage Parallel Instances Performance Limits
By
–
I don't think I ever hit it and I'm a pretty heavy user (I run 3-5x in parallel sometimes), there probably is at some point but not if you are a reasonable user
-
GPT-5 Pro Pricing: Teams Plan and Credit Options
By
–
So double checked, with Teams ($25 annual, $30 monthly, 2 seats minimum), of GPT-5 Pro you get 15/month and you can buy $20 worth of credits for 10 queries. I am not saying this is a great deal btw, just if you wanted to try it without going for the $200 tier. I still think $200
-
ChatGPT Pro subscription value assessment and pricing models
By
–
Only 15/month https://
help.openai.com/en/articles/12
003714-chatgpt-business-models-limits
… so for me, pro is still worth it -
GPT-5 Pro Teams Plan Alternative Pricing Option
By
–
Btw, if you want GPT-5 Pro, but don't want to pay $200/month, you can get a Teams (called Business) plan for a bit more money (2 seats minimum) and you get some GPT-5 Pro access + you can top up the credits for more requests.