The correctness of our solution to FirstProof problem 7 is also confirmed by Jim Fowler, the mathematician who conjectured the question originally! See github.com/google-deepmind/s… for all our transcripts and solutions (both correct and incorrect ones!) as well as public discussion of P7 at icarm.zulipchat.com/#narrow/….
@lmthang
-
Aletheia AI Solves Open Math Problem P7 Successfully
By
–
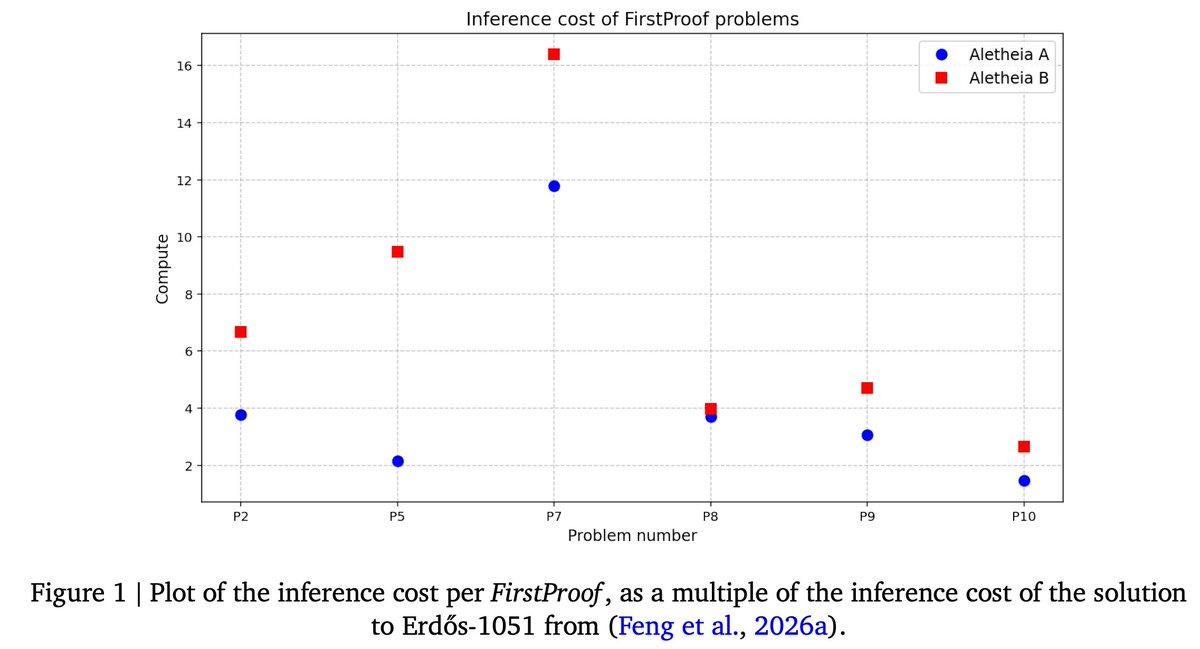
This is a remarkable milestone in which our agent can work on a research problem for a very long time, then come back and tell us if it has succeeded or failed! We visualize the inference cost Aletheia decided to spend on each candidate solution (as a multiple of the inference cost of for solving Erdős-1051, see our previous work nitter.net/lmthang/status/2018354…). P7 is extremely interesting. It has been an open problem for several years, and nobody else came close to solving it in the FirstProof contest per @tonylfeng. We initially thought Aletheia had no chance; turned out it was right! Aletheia spent most compute on P7, 16x amount we used for Erdős-1051. Remarkably, per @kimshmath, "This was the first case that I have ever seen that an AI applies several deep mathematical results (by Cartan/Leray/Borel/Atiyah/Quillen/Novikov/Kasparov…) flawlessly. It is a very unique instance."
-
Aletheia solves 6 of 10 FirstProof problems using Gemini DeepThink
By
–
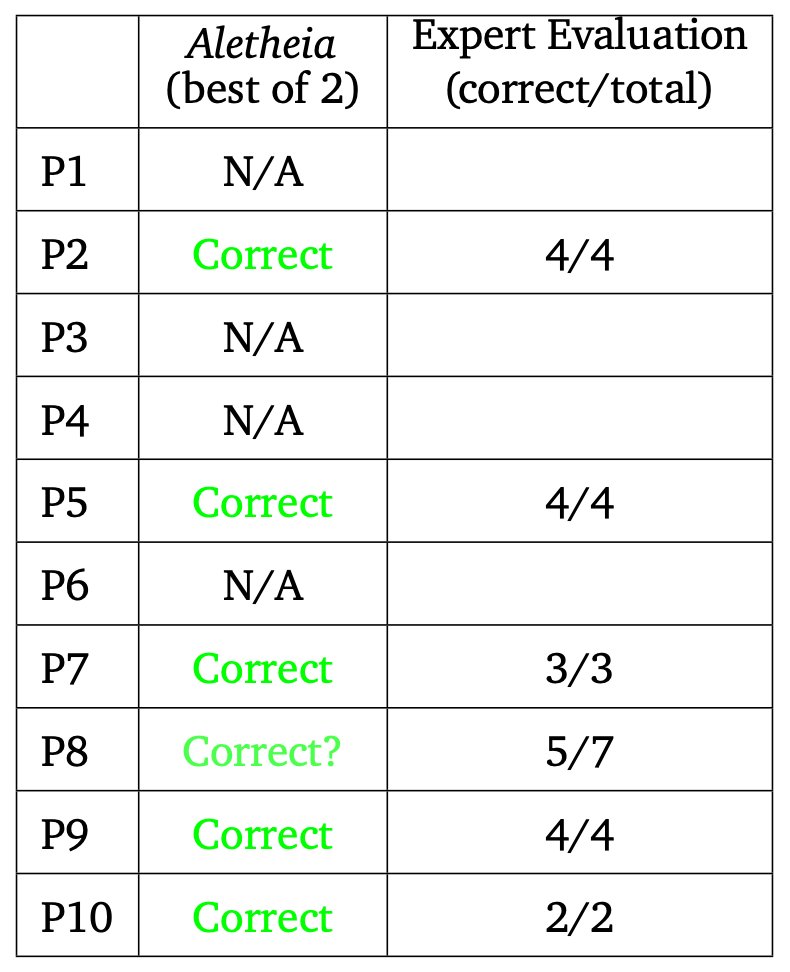
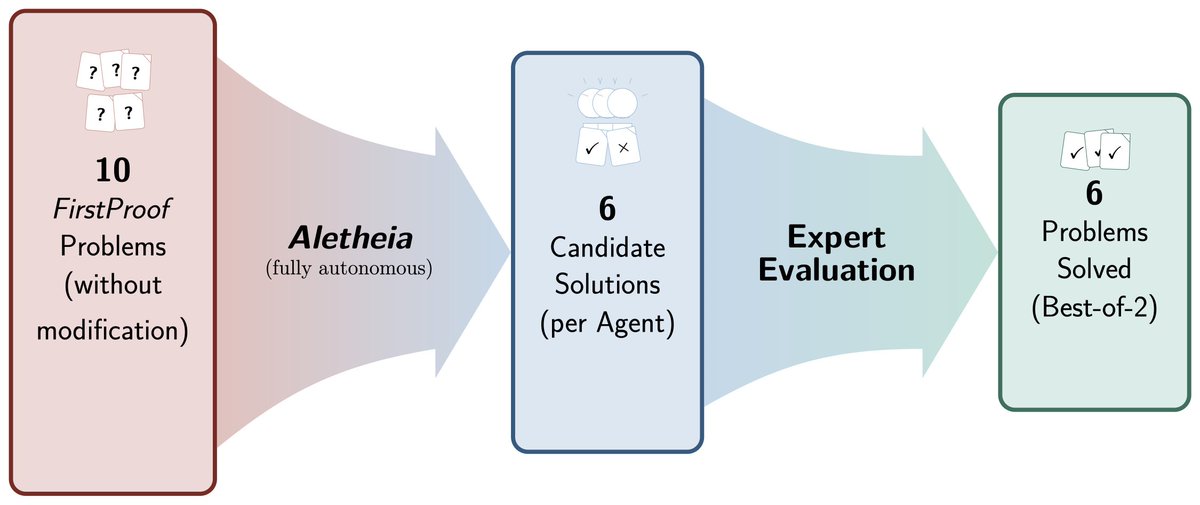
We ran two Aletheia versions (differing only by base model) powered by Gemini #DeepThink. Together, they solved 6/10 problems (2, 5, 7, 8, 9, 10) per majority expert assessments. Full transparency on our FirstProof interpretation and experiments: arxiv.org/abs/2602.21201. Evaluation is extremely hard! Only a handful of experts can even understand these problems. As such, we have conducted our study very carefully! Crucially, our solutions were generated without any human intervention and submitted within the timeframe of the FirstProof challenge. The lead author of FirstProof confirmed that fact in the public Zulip discussion of our solutions icarm.zulipchat.com/#narrow/….
-
Aletheia Math Agent Solves Hard FirstProof Problems Autonomously
By
–
Thrilled to share: #Aletheia, our math research agent, just solved 6/10 notoriously hard FirstProof problems autonomously, the best result in the inaugural challenge! To me, this is even bigger than our historic IMO-gold achievement last year; these problems challenge even top mathematicians. We share our results transparently, see paper and full thoughts in the thread. 👇
-
Gemini 3.1 Pro Meme Video
By
–
Gemini 3.1 Pro be like pic.twitter.com/ZwCauGxLar
— Google (@Google) 19 février 2026Gemini 3.1 Pro be like
-

Human-AI Interaction Framework for Mathematics Assistance
By
–
Yes, we provided 3 things for AI-assisted math:
* Human-AI interaction (HAI) card (photo), inspired by model cards
* Full transcripts https://
github.com/google-deepmin
d/superhuman/tree/main/aletheia
…
* A label for novelty-autonomy, inspired by SAE Levels of autonomy, see #Aletheia paper https://
arxiv.org/abs/2602.10177 -
Google DeepMind’s Rapid Progress: From Bard to DeepThink
By
–
Again, it has been a privilege witnessing the relentless progress from Google Brain to Google DeepMind :
* ChatGPT -> Bard announcement (Mar 2023): 100 days
* Announcement of IMO-gold achievement -> DeepThink v1 launch (Jul 2025): 10 days
* Announcement of Aletheia agent & -

Gemini Deep Think Powers Major Discoveries in Math Physics Computing
By
–
and in case you missed it, here's how Gemini Deep Think has powered various discoveries from maths, to physics and computer science!
-
AI Models Achieve 76.7% on IMO ProofBench Mathematics
By
–
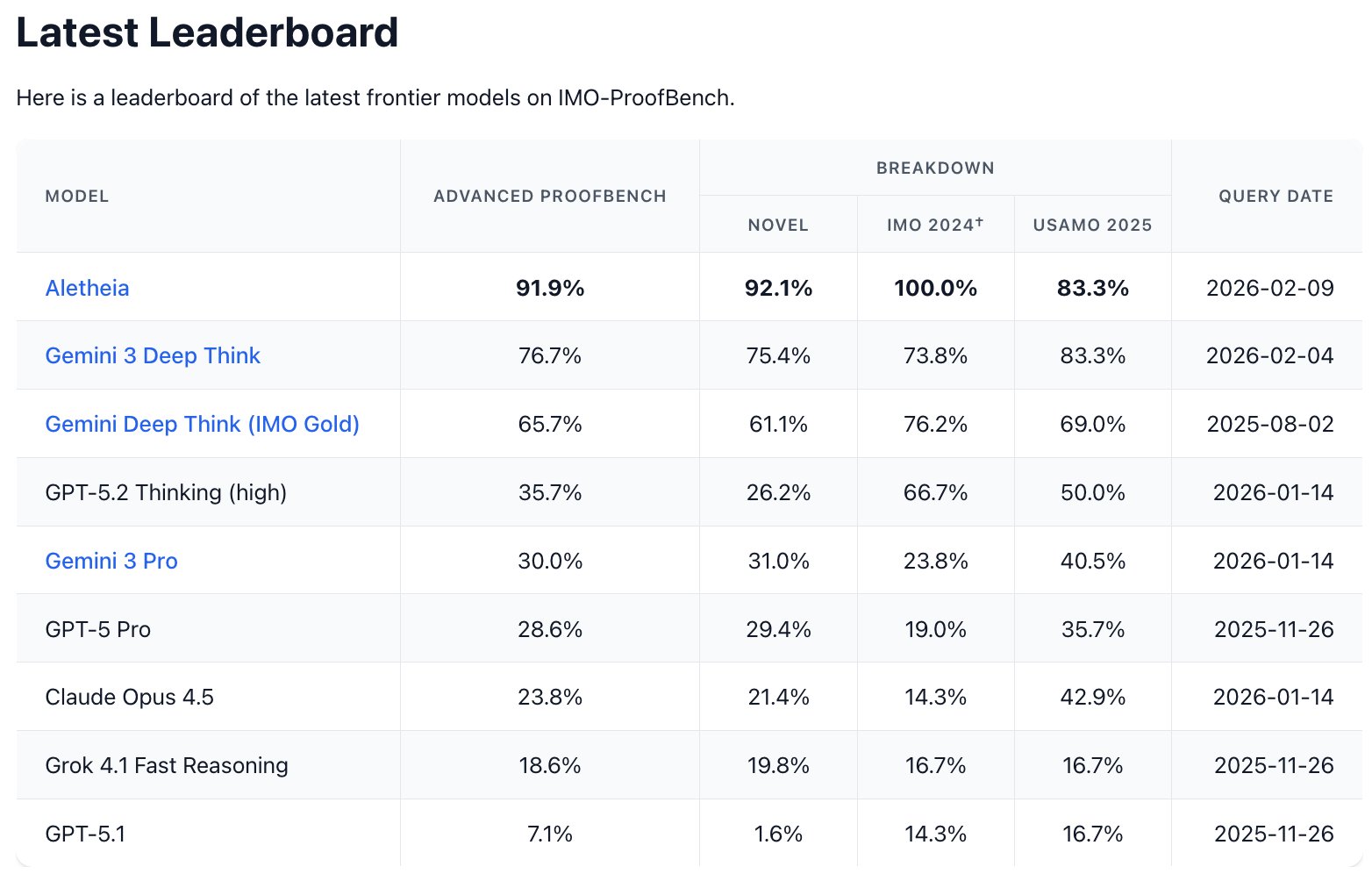
And here's the little leaderboard that we maintain on IMO ProofBench in case you haven't seen it.
* Our IMO-gold model (non-public, Jul 2025) got 65.7%. * Gemini 3 Deep Think (public, Feb 2026) now got 76.7%.
* Aletheia (non-public) with inference-time scaling law + -
DeepThink Achieves IMO Gold Using Inference-Time Scaling
By
–
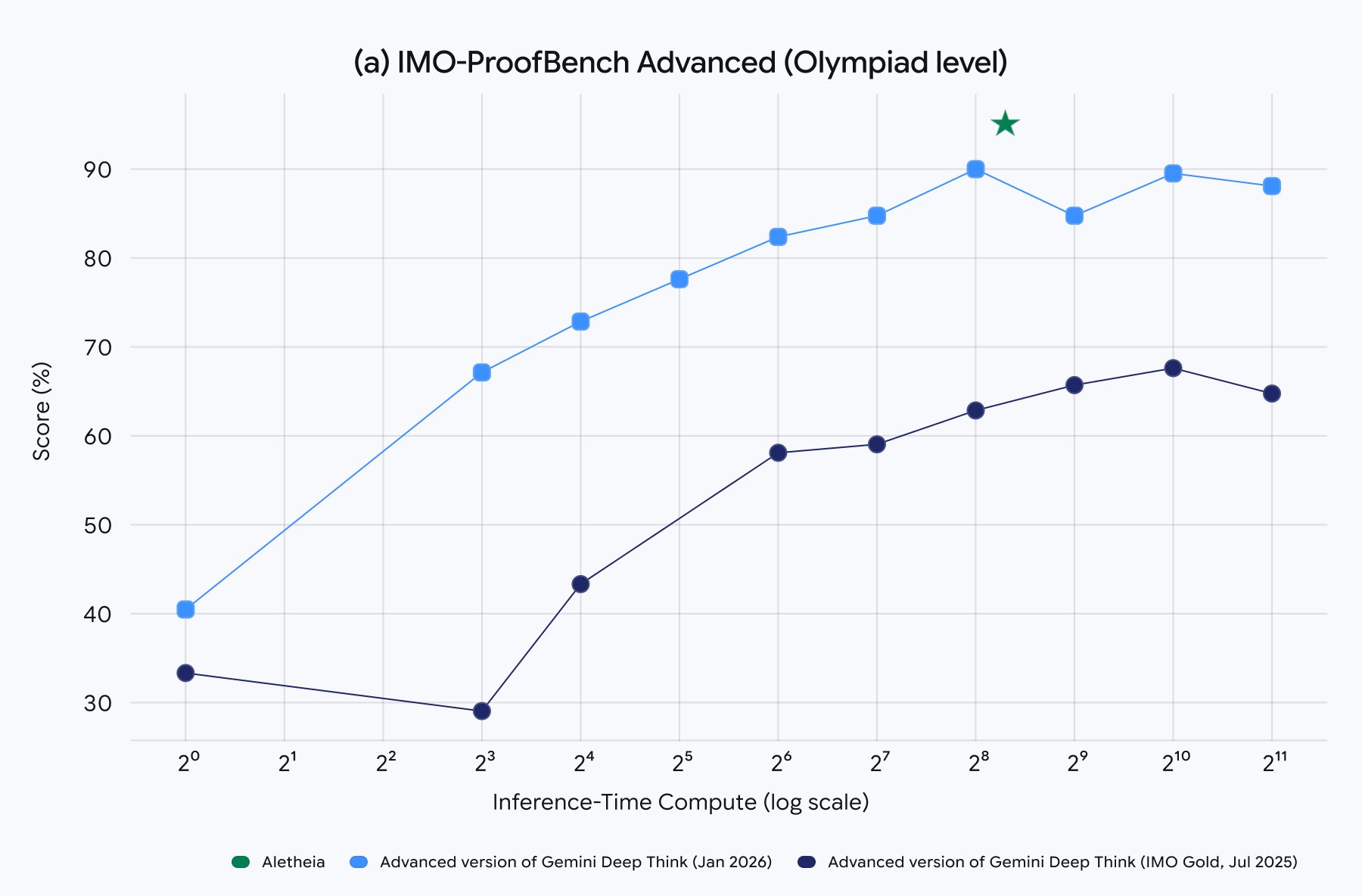
DeepThink is exceptionally good when powered by an inference-time scaling law that we showed in our Aletheia paper https://
arxiv.org/abs/2602.10177! These were benchmarked on our IMO-ProofBench graded by experts, which was the north-star metric leading to our IMO-gold achievement. Amazing