pod with @chai_research
! Outlasting @NoamShazeer
, crowdsourcing Chat + AI with >1.4m DAU, and becoming the "Western DeepSeek": https://
latent.space/p/chai Chaiverse is what @lmarena_ai would be if it were taken very very seriously (backed by $1m in prizes) and every new model
@latentspacepod
-
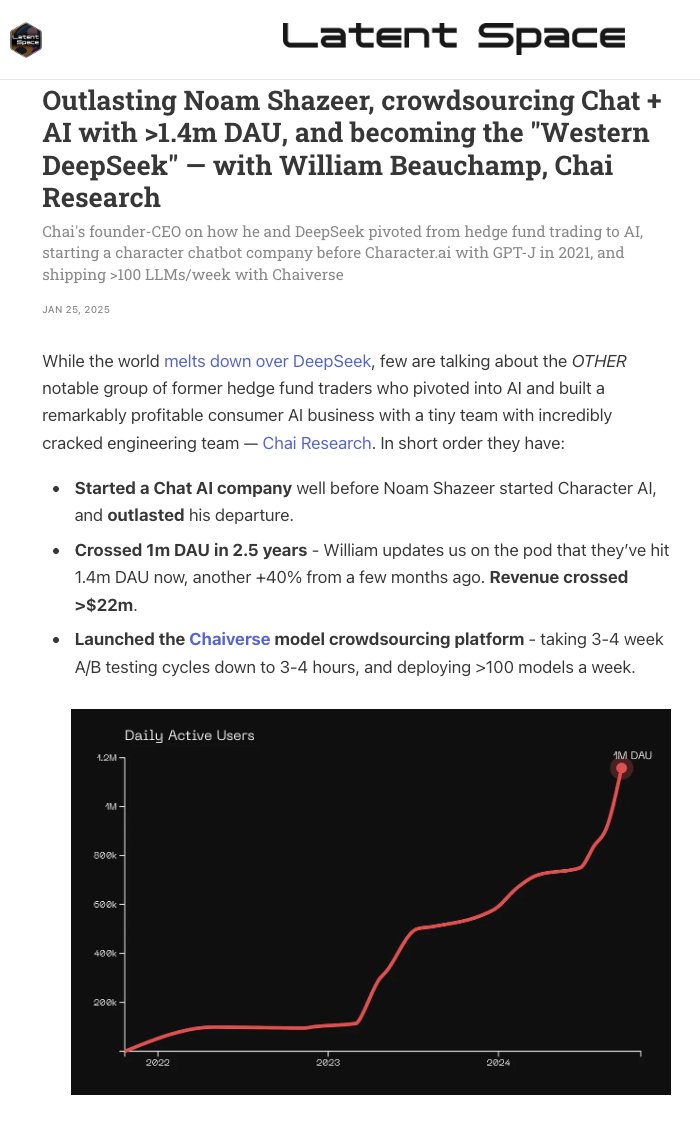
Chai: Western DeepSeek competitor with 1.4M DAU chatbot
By
–
-

What is an AI Engineer? New Short Form Video Format
By
–
first run of "What is an AI Engineer?"
— Latent.Space (@latentspacepod) 25 janvier 2025
Experimental new short form video format we are trying out – didn't publish on yt bc need to rehearse more but feedback welcome
(thanks to @lizziepika for the lightboard!!) https://t.co/OeTT4JMRcD pic.twitter.com/7k4saEeyiXfirst run of "What is an AI Engineer?" Experimental new short form video format we are trying out – didn't publish on yt bc need to rehearse more but feedback welcome (thanks to @lizziepika for the lightboard!!)
-
Reasoning Less Competitive Moat Than Expected in 2025
By
–
2025's biggest surprise so far: Reasoning is less of a moat than anyone thought.
-
Cold email idea to Yeezy AI team suggested casually
By
–
hmm @fanahova maybe we just cold email ai.team@yeezy.com
-
DeepSeek v3 and SGLang: Mission Critical Inference
By
–
: Everything you need to run Mission Critical Inference (ft. DeepSeek v3 + SGLang) https://
latent.space/p/baseten We chat with @amiruci and @yinengzhang about the Chinese Whale Bro drop of 2024: – @deepseek_ai v3
– @lmsysorg
's SGLang
– the Three Pillars of Mission Critical -
OpenAI o1: Revolutionary reasoning model beyond chat capabilities
By
–
OpenAI o1 isn’t a chat model (and that’s the point)
-
New Podcast Episode: o1 Skill Issue Discussion with Ben
By
–
After the success of the o1 skill issue post, we recorded a quick podcast with Ben and @daniel_mac8 . Live now! (link below for the algo gods)
-
GPU Scarcity Ends: 2024 Compute Rental Price Collapse
By
–
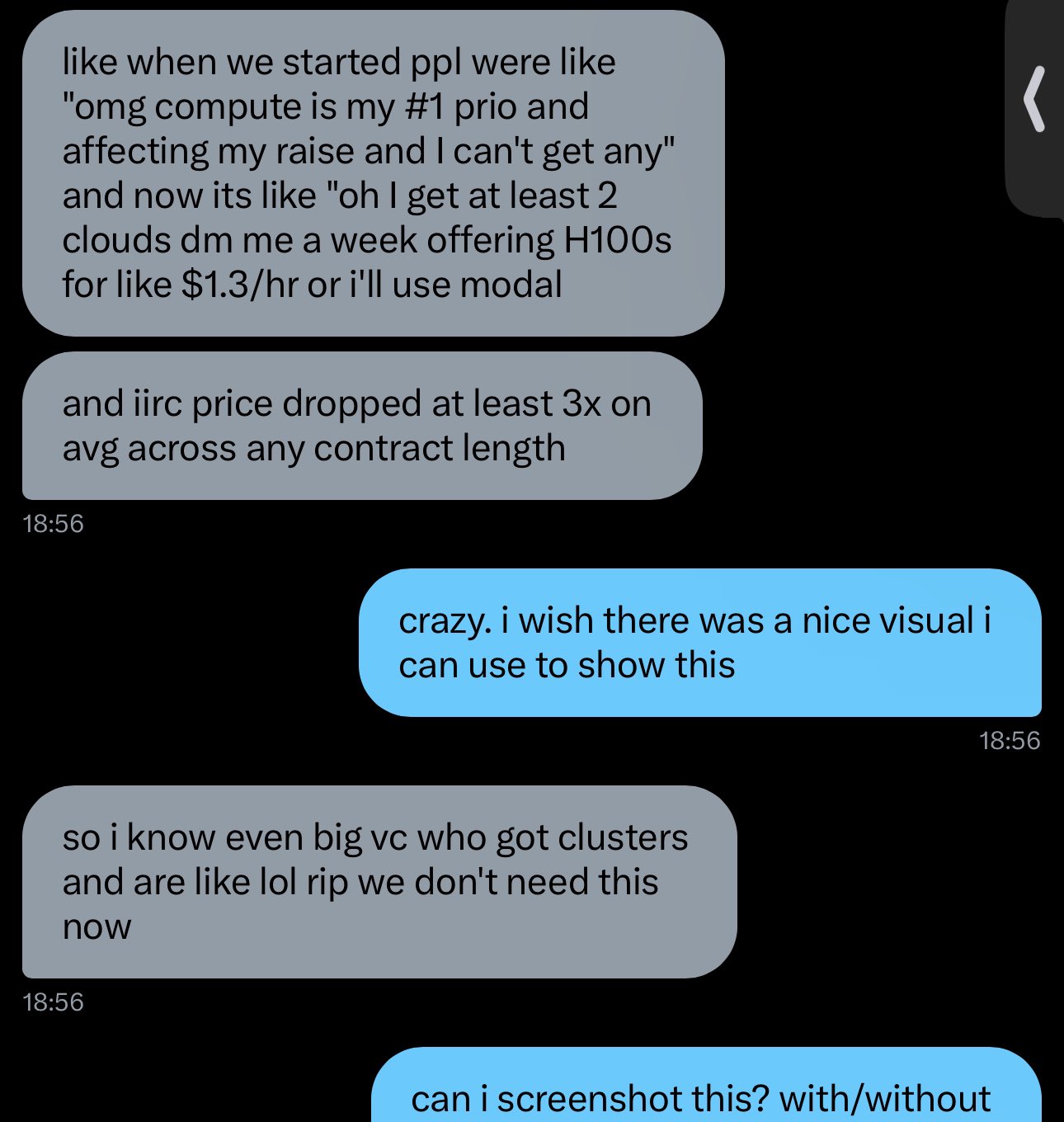
RIP GPU scarcity*, 2023-2024 followup to the @picocreator guest post documenting the gpu rental price collapse of 2024 nobody is plotting this bc the people with the data are desperately trying to sell their overcommitted compute *for small clusters. 100k gpus in one cluster
-
ComfyUI Startup Journey: AI Engineering for Creative Tools
By
–
pod: AI Engineering for Art! https://
latent.space/p/comfyui First pod of the year, with comfyanonymous face reveal! Going over the origin story of @ComfyUI (now a startup, competing with multiple @ycombinator startups like @comfydeploy
), dishing tea on working at @StabilityAI in