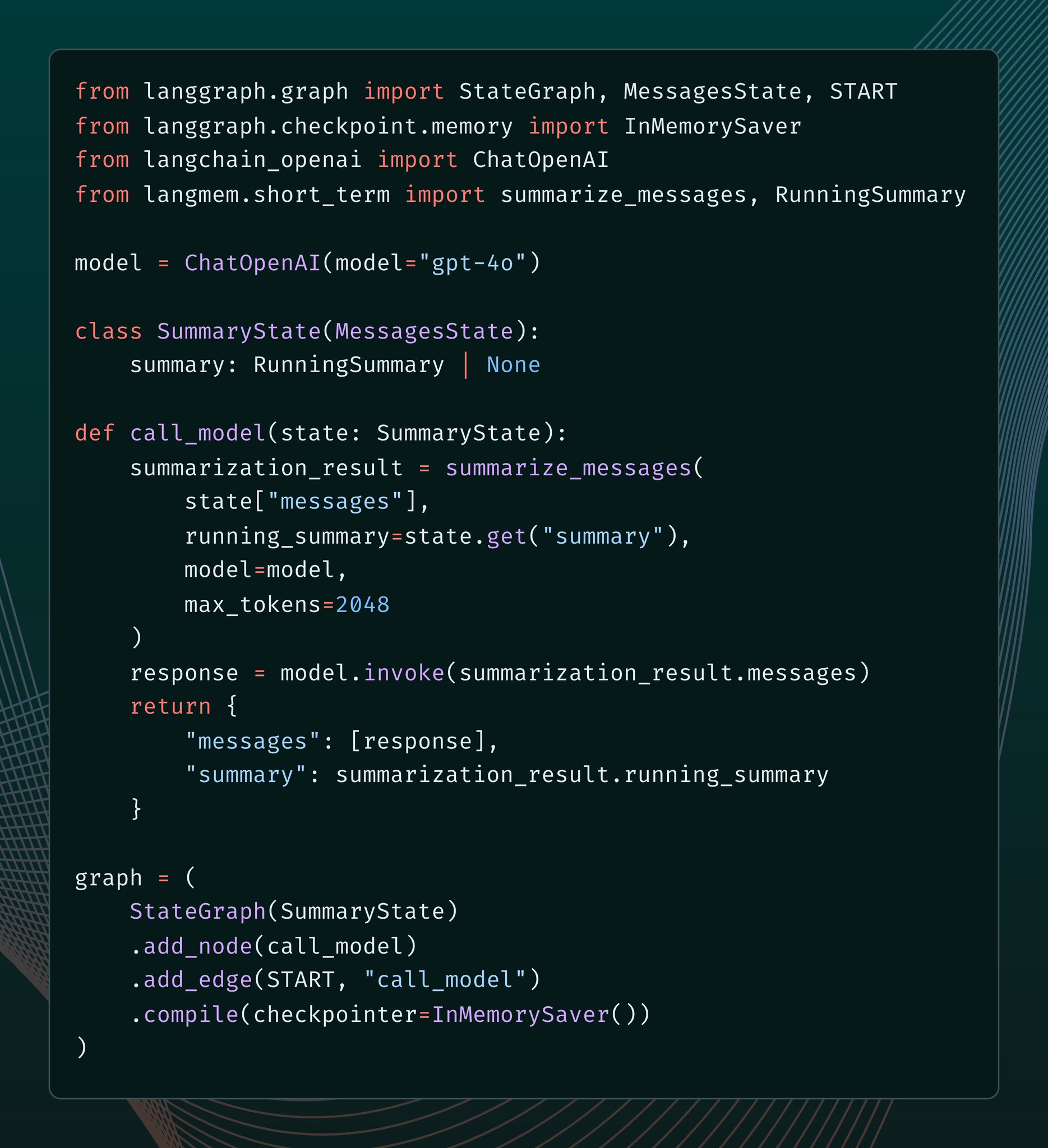
we get a lot of questions about managing long context some utils here that should help with that!
@hwchase17
-
LangChain Community Framework Contributions Recognition
By
–
LangChain community**** Not an official team effort, don’t want to take any credit – all goes to the developers of this!
-
LangManus Open Source Project Replicates Manus Framework
By
–
🦜🤖LangManus
— Harrison Chase (@hwchase17) 20 mars 2025
You had to know it was coming!
This community effort attempts to replicate Manus using the LangStack (LangChain + LangGraph)
Still early innings – but check it out here!https://t.co/2APEonZTRg pic.twitter.com/5BOTHdhKn1LangManus You had to know it was coming! This community effort attempts to replicate Manus using the LangStack (LangChain + LangGraph) Still early innings – but check it out here! https://
github.com/langmanus/lang
manus
… -
Servlet Installation UX Lacks Consumer-Friendly Design
By
–
tried it out quickly, some feedback: it wasnt obvious how to install a servelet and didnt feel super consumery, was still pretty dev focused
-

LangChain Hiring: Join Team Shipping AI Innovation
By
–
We do a lot at LangChain! Nice to see a bunch of trending repos (Local Deep Research with Ollama) and trending developers @nfcampos @BraceSproul @vadymbarda @RLanceMartin If you want to join a crew that ships… we're hiring! https://
langchain.com/careers -

Graph Performance Optimization for Large-Scale Node Processing
By
–
We’re seeing more and more graphs with lots of nodes – this speeds those up a lot
-
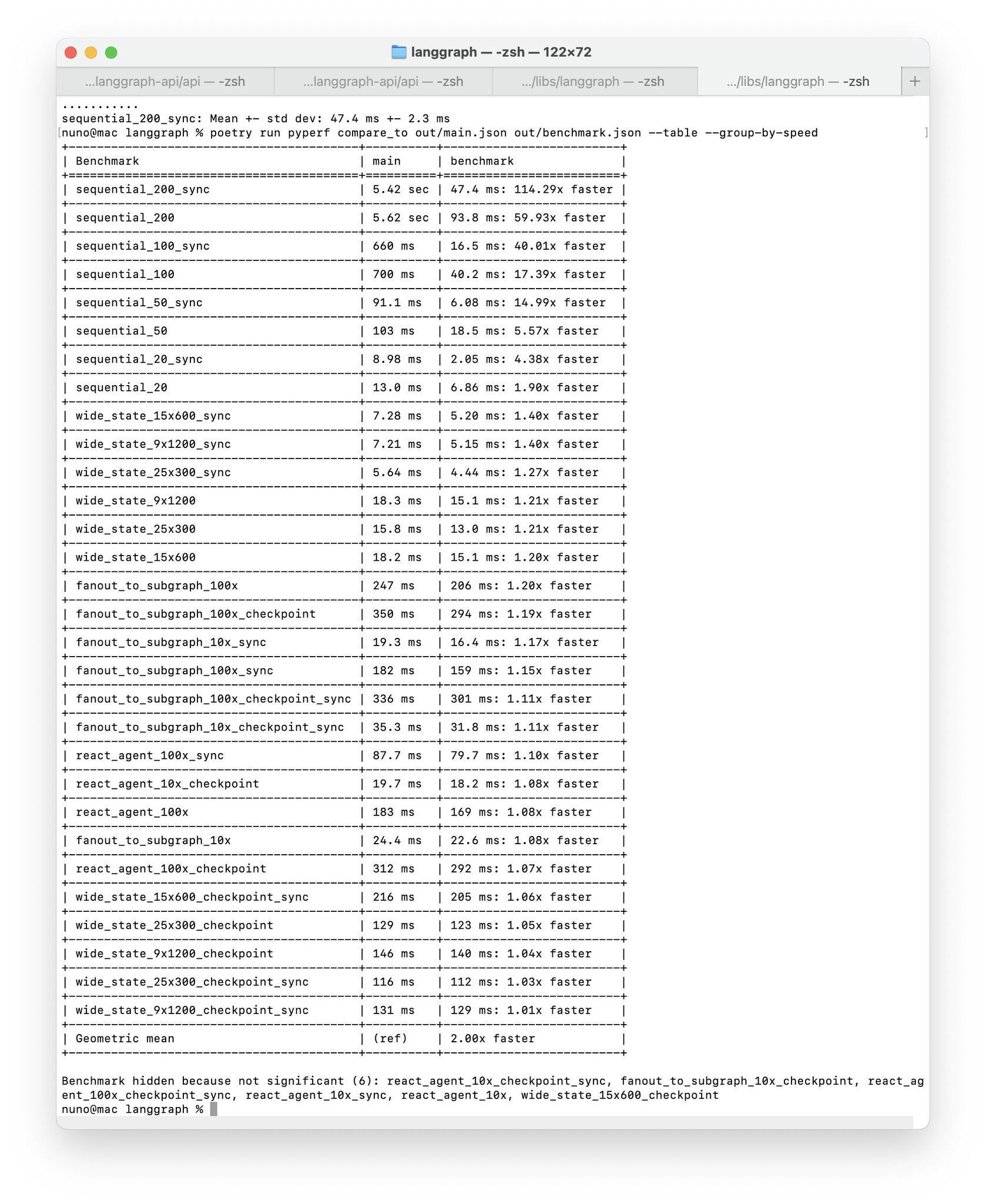
Graph Performance Optimization for Large Node Networks
By
–
We’re seeing more and more graphs with lots of nodes – this speeds those up a lot
-
Building AI Agents: The Next Development Challenge
By
–
Now you just need someone to build those agents
-
Prompts Now Visible and Editable in Agent Node UI
By
–
You can now see prompts attached to nodes, and edit them directly in the ui Agent building isn’t just engineering – there’s a big prompting/visual component to it, this is a step in that direction
-

Evaluating AI Agents with LangSmith and Writer CTO
By
–
Evaluating agents One of the trickiest parts of building agents is evaluating agents We're tackling this with LangSmith. I'll sit down with Writer CTO Wassem Alshikh **tomorrow** in SF to talk about this See ya there! https://
lu.ma/x7ohaj2c