An interesting detail is that for the Instant model we continue to use version 5.3
@dotcsv
-
Image V2 AI Transforms Graphics Generation and Recontextualization
By
–
Now, what a wild thing this image v2 is for updating and recontextualizing images and graphics from others on the fly
-
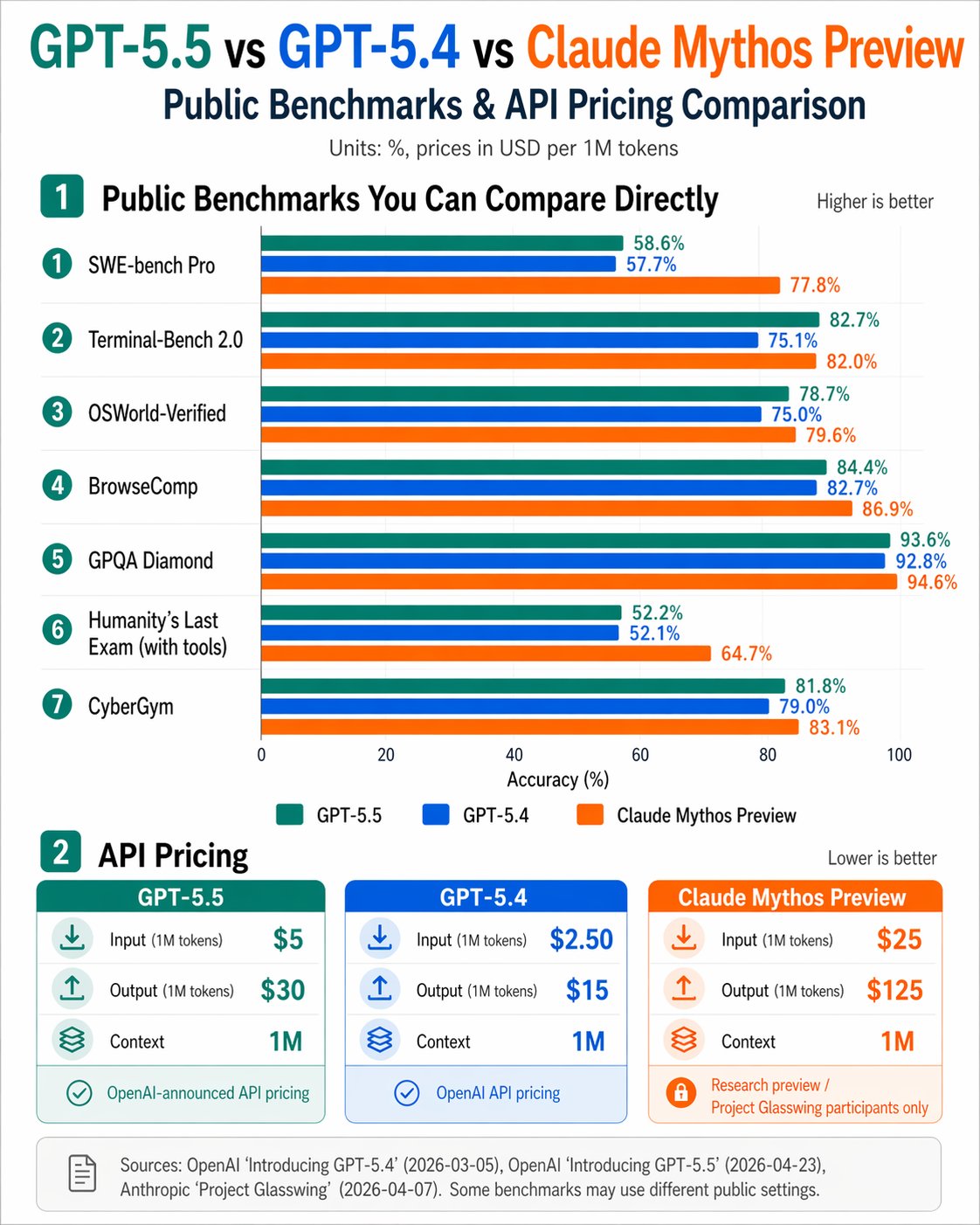
GPT 5.5 vs Mythos: Benchmark Performance Comparison Analysis
By
–
A false narrative is being shared that GPT 5.5 ties with Mythos on several benchmarks as if that made them equivalent. What's being overlooked is that GPT 5.4 was already on par with Mythos in those benchmarks, except for Terminal Bench 2.0…
-
Testing AI Model Performance Beyond Benchmarks Real Evaluation
By
–
Now it's time to test the model to draw clear conclusions not just from benchmarks, but from the real vibes of working with it. And also wait for external evaluations on the rest of the benchmarks from those who go on testing via the API. We'll keep you posted
-
GPT 5.5 Frontend Design Issues Persist Despite Updates
By
–
En mi carta a Santa Claus puse que ojalá GPT 5.5 arreglara por fin el problema de diseño de frontends, pero claro… en Abril no viene Santa Claus.
— Carlos Santana (@DotCSV) 23 avril 2026
Noto ligeras mejoras pero ahí están, las cajas azules rodeándolo todo.https://t.co/BMoRdNcIxDIn my letter to Santa Claus, I wrote that I hoped GPT 5.5 would finally fix the frontend design problem, but of course… Santa Claus doesn't come in April. I notice slight improvements but there they are, the blue boxes surrounding everything.
-
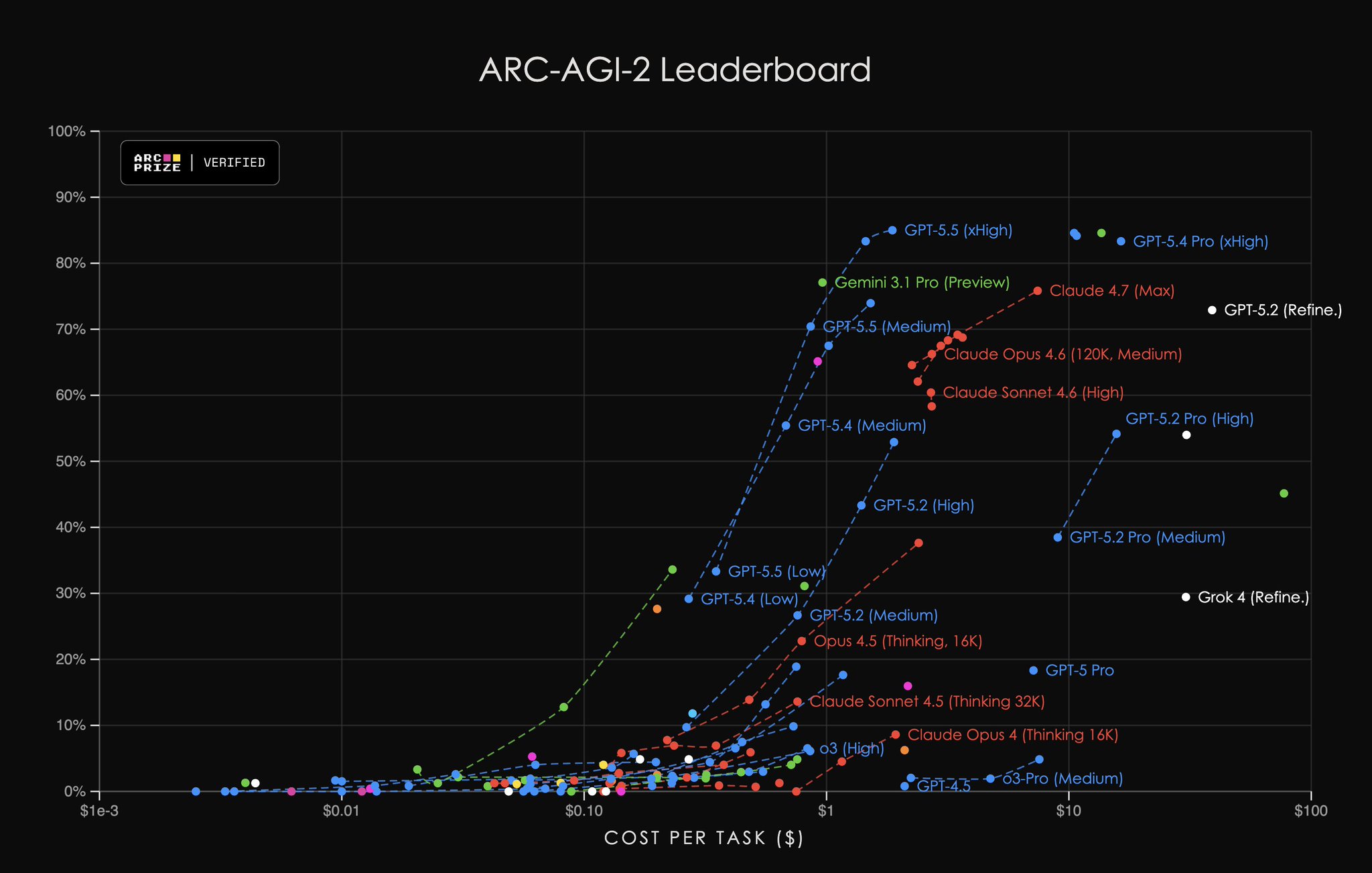
ARC-AGI 5.5 outperforms Gemini 3.1 Pro at reasoning
By
–
In ARC-AGI 5.5, it is positioned at the cost frontier of Gemini 3.1 Pro but achieving a better score in its highest reasoning levels.
-
OpenAI’s Rapid GPT Release Pace Raises Marketing Concerns
By
–
I'm sure that GPT 5.5 by vibes will be an excellent model, just like its predecessor was. And hey, OpenAI's pace of progress is excellent if we think about the fact that the previous one came out a month and a half ago! BUT FOR GOODNESS' SAKE OPENAI STOP WITH THE OVER-THE-TOP
-
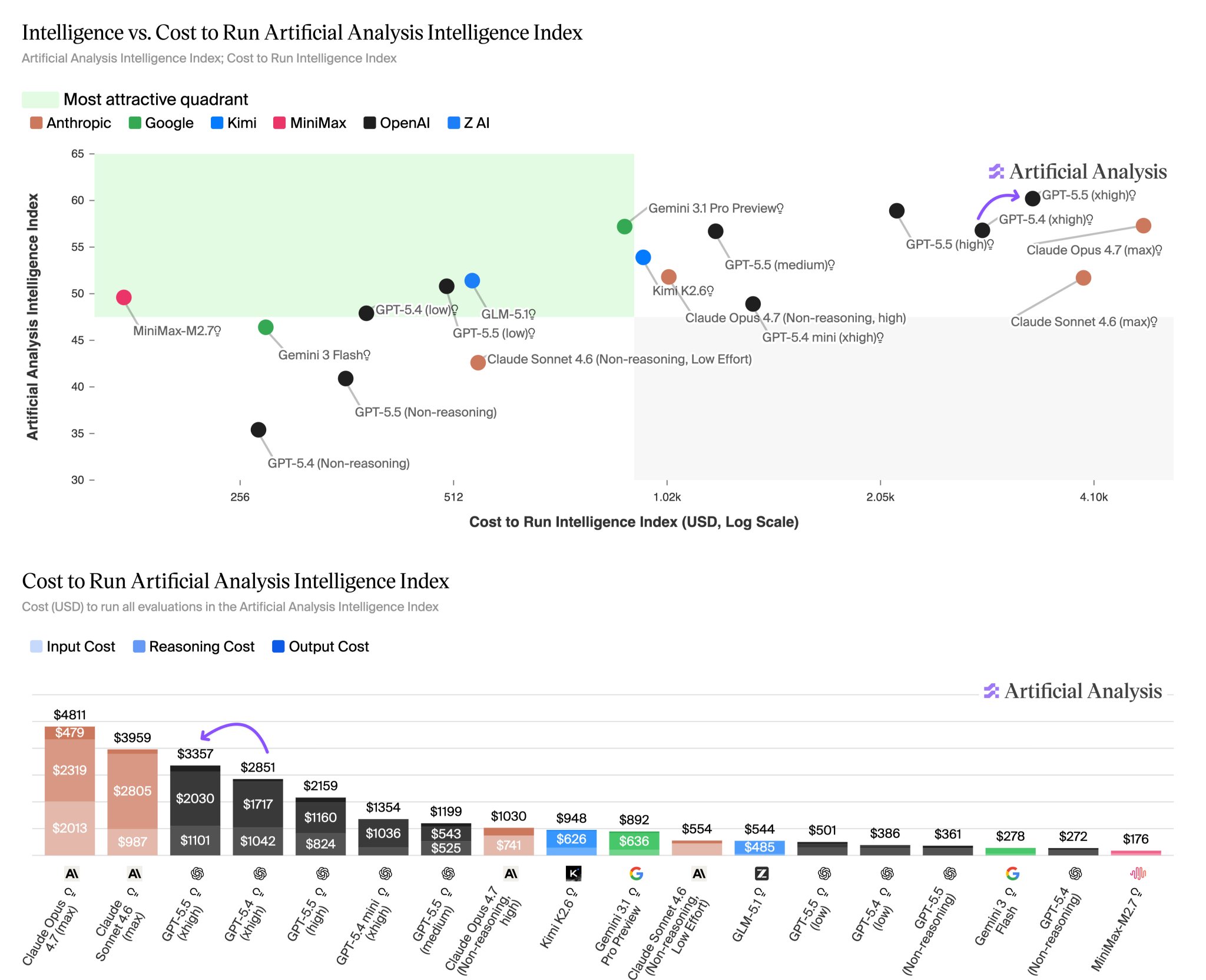
New Model Costs 20% More Than GPT 5.4 Despite Token Efficiency
By
–
Because the price of the model doubles (!!) its predecessor, buuuut this is something that's mitigated by the more efficient use of tokens But in combination, as a result, it leaves us with a model that's 20% more expensive than GPT 5.4 xhigh when it comes to evaluating
-
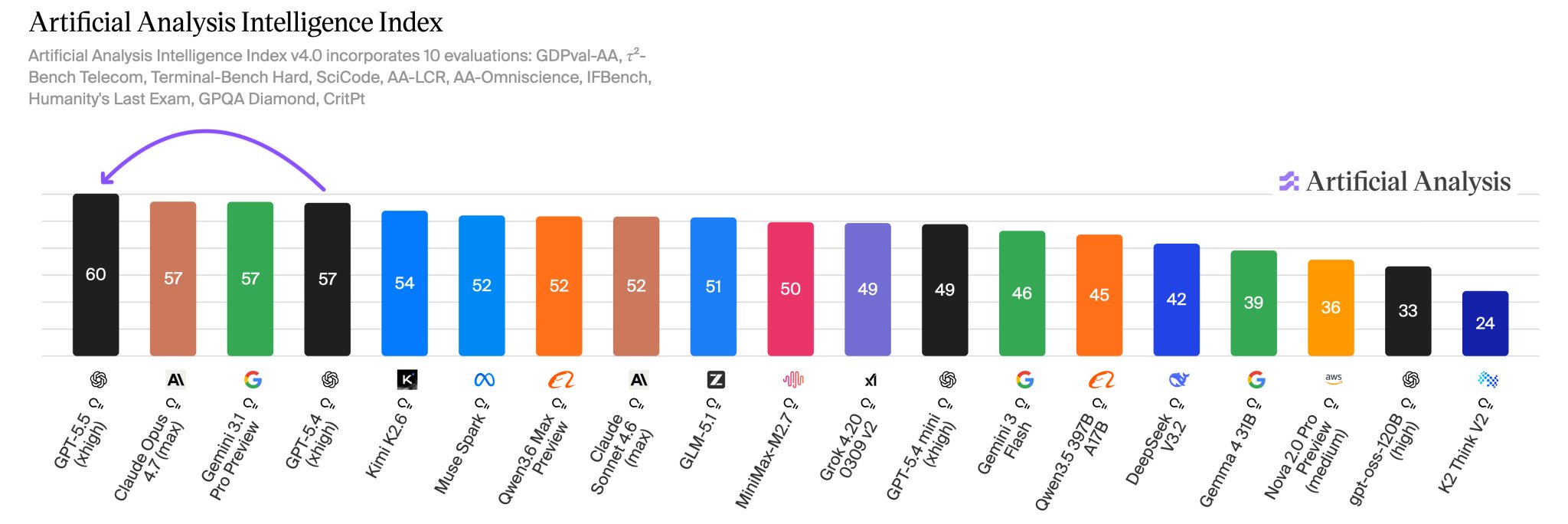
New AI Model Shows Better Benchmarks Despite Higher Costs
By
–
What is clear is that it is a better model in terms of benchmarks and based on the feedback I've been seeing for days from insiders I trust who have been testing it. Bring it on. That said, it is also a more expensive model.
-

GPT Model Performance Benchmarking and Marginal Improvements Analysis
By
–
A benchmark that captures the evolution of models in real office work well is OpenAI's own GDPval, and notice that here the model improves only marginally over the previous one, but the thing is that it really even in WINS achieves less than GPT 5.4. Honestly, I think there are