What madness that they've got a robot working 8 hours. Oh well, I'm setting Codex with a /goal for tonight and leaving it to work while I sleep.
@dotcsv
-
Identifying visual artifacts in ChatGPT image generation
By
–
¿Habéis detectado ya cuál es el "tinte amarillo" de la nueva versión de imágenes de ChatGPT? Yo lo tengo claro Os dejo un examen visual, pero cuidado porque una vez lo veais no parareis de notarlo.
-
DeepMind prototype explores new AI-human interface paradigms
By
–
Muy buena demostración de DeepMind del largo camino que aún nos queda por hacer (y deshacer) para reimaginar las interfaces que usamos con IA!
— Carlos Santana (@DotCSV) 12 mai 2026
En este caso un prototipo de cursor inteligente que pueda entender, según dónde apunta el usuario, su intención.pic.twitter.com/guuR9Lj1yrA very good demonstration from DeepMind of the long road we still have ahead (and behind) to reimagine the interfaces we use with AI! In this case, a prototype of an intelligent cursor that can understand, based on where the user points, their intention.
-
AI identifying human errors in benchmark testing
By
–
And I say irony because of the fact that we, humans, design tests to evaluate the capabilities of AI, and then it’s the AI that comes along to point out the errors made by humans in our tests.
-

GPT-5.5 evaluation errors revealed in FrontierMath benchmark
By
–
The irony. Using AI (GPT 5.5), errors have been identified that would affect 1/3 of the problems in the FrontierMath benchmark Tiers 1-4. This could represent a shift in the evaluations of AI's mathematical capabilities, which may be underestimated.
-
ChatGPT 5.5’s Math Skills Analyzed
By
–
I write about this in more detail in a blog post with a guest contribution from Isaac Rajagopal, a student at MIT on whose work ChatGPT built, who gives his assessment of the level of mathematical ability displayed by the model. https://
gowers.wordpress.com/2026/05/08/a-r
ecent-experience-with-chatgpt-5-5-pro/
… -
LLMs’ Math Progress Accelerates Rapidly
By
–
It's surprising to see the pace of progress of LLMs (which until not long ago were very bad at math) achieving ever greater milestones. Take a look at the graph above. The progress curve is getting faster and faster. I'll leave the link to the paper here: https://
arxiv.org/abs/2605.06651 -

Google reclaims lead in FrontierMath Tier 4
By
–
LEADER in FRONTIER MATH T4! New record in one of the most challenging math benchmarks -FrontierMath Tier 4- where Google has just reclaimed the lead with a 47.9% !!, stealing the position from GPT 5.5 Pro It does it with its new math agent
-
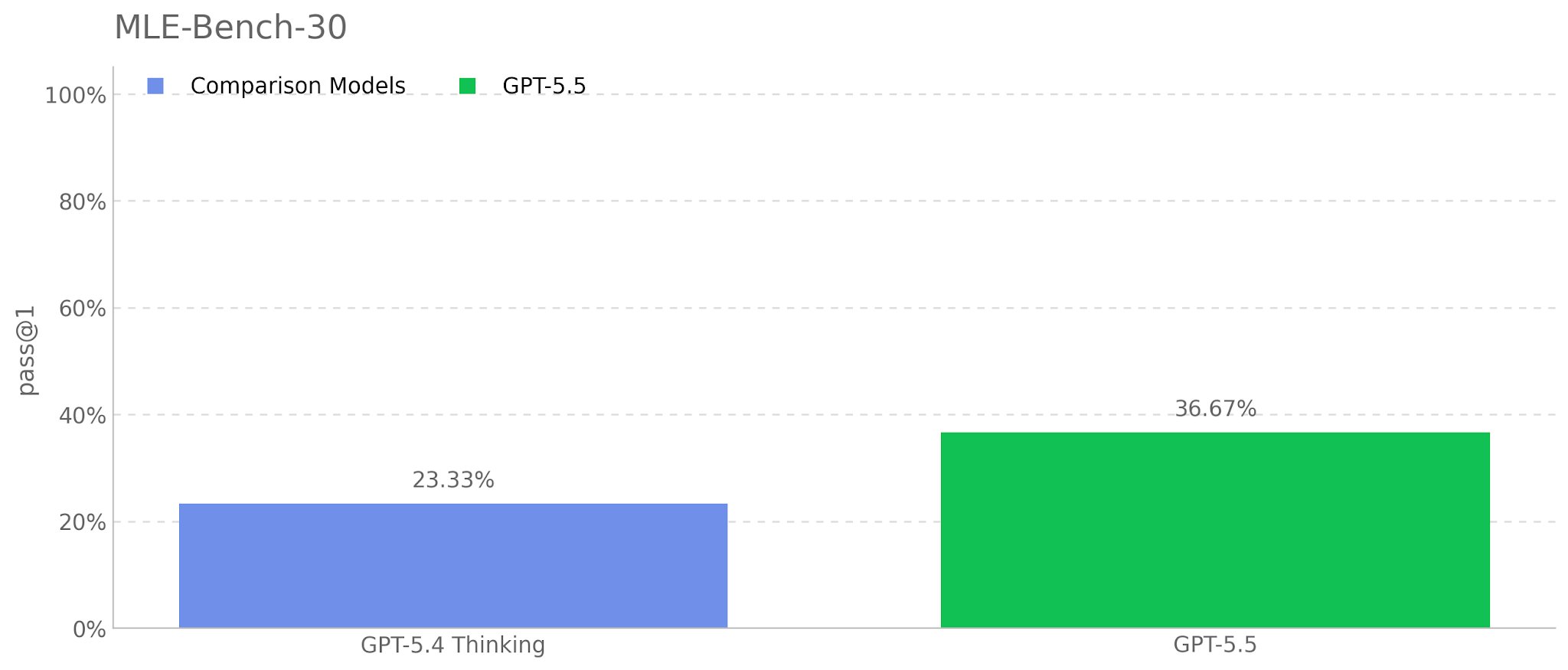
GPT 5.5 Impresses in Deep Learning Research
By
–

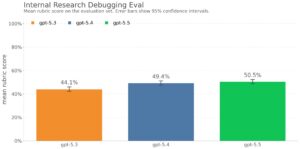
After another week of intensive work with GPT 5.5, I’m once again confirming my initial conclusions: it’s an impressive model. For deep learning auto-research tasks, the improvement over versions 5.2 and 5.4 is highly noticeable! It’s not just about execution and implementation—
-
OpenAI Releases Three New Voice Models
By
–
🔴 ¡NUEVOS MODELOS de VOZ de OPENAI!
— Carlos Santana (@DotCSV) 7 mai 2026
Tres nuevos modelos de voz en tiempo real:
👉GPT-Realtime-2: Primer modelo de voz con el razonamiento de GPT-5!
👉GPT‑Realtime‑Translate: Traducción en tiempo real
👉GPT‑Realtime‑Whisper: STT en tiempo realpic.twitter.com/SI0HCKZ4ULNEW VOICE MODELS FROM OPENAI! Three new real-time voice models: GPT-Realtime-2: First voice model with GPT-5 reasoning! GPT‑Realtime‑Translate: Real-time translation GPT‑Realtime‑Whisper: Real-time STT