
Users want: H3 = Equal partnership (what workers want) not full replacement. It’s common sense really.
@deeplearn007
-
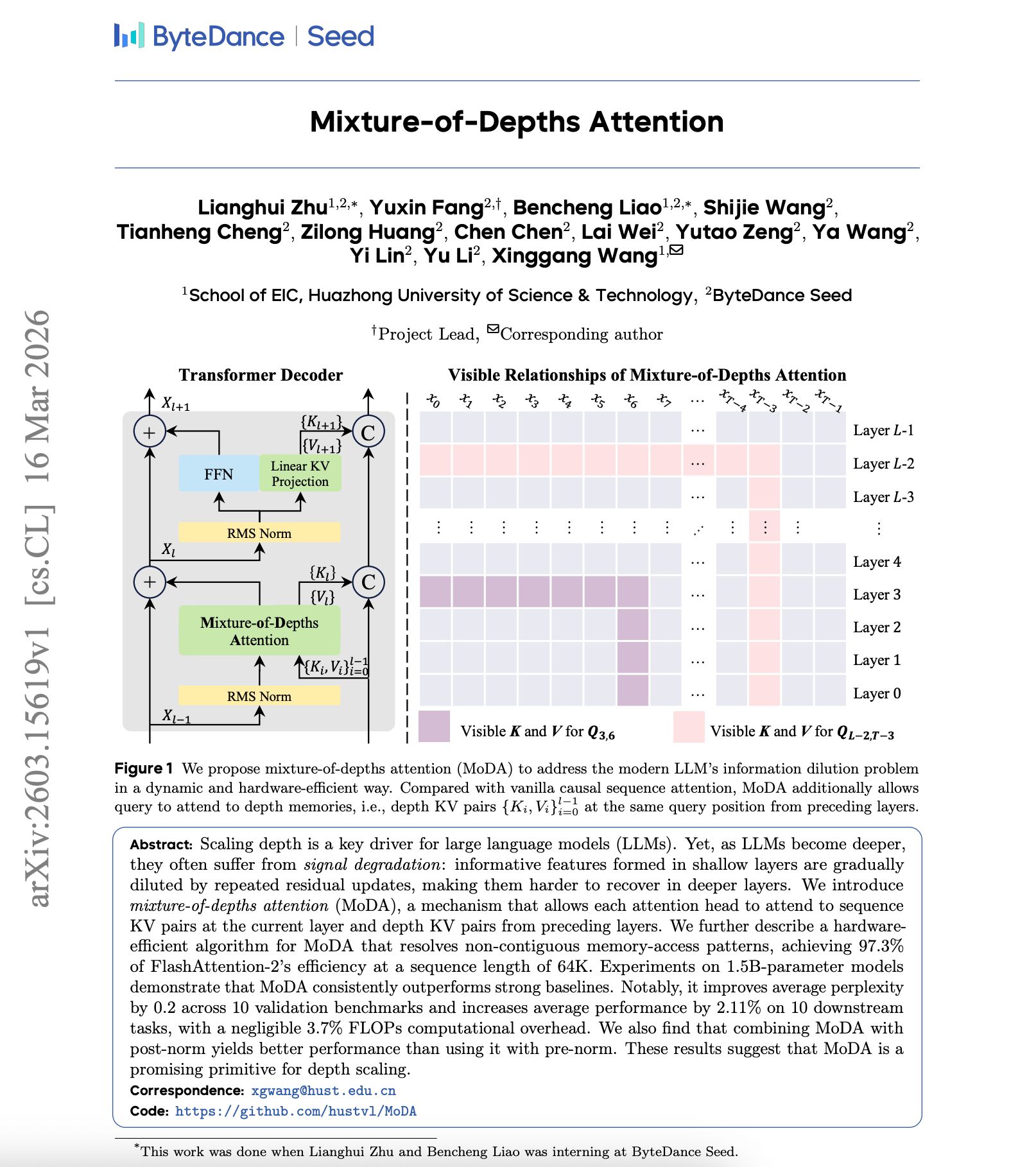
Self Attention Mechanisms in Transformers and LLMs
By
–
Improving Transformers with Self Attention Mechanism- this technique is at the heart of GPT and most LLMs. I would not imply that this issue is their biggest problem though. That said no one has to date managed to replace them with a viable alternative. Maybe that changes but
-
Two-Year-Old AI Study Now Obsolete and Less User Friendly
By
–
Clickbait on 2 year old study looking at AI is now obsolete and less user friendly.
-

AI Technology Evolution and Increased User Accessibility Over Two Years
By
–
AI and its usage has changed greatly deal since this 2 year study which itself would have been a look back on AI tech that was less user friendly
-
GPT 5.5 Delivers What GPT 5 Failed to Achieve
By
–
To be fair GPT 5.5 has been much more of what GPT 5 was supposed to be but 5 failed to deliver.
-
UBI and AI: Economic Models for the 2030s
By
–
UBI relies on taxing the robotics and AI and redistribution of that to those who were displaced. We’ll see in the 2030s which way this goes. Whether AI creates new jobs and increases demand or whether a new economic model is needed.
-

GPT 6.0 versus GPT 5.5: Evaluating Real Advancement Claims
By
–
It depends whether GPT 6.0 = GPT 5.0 in which case this dude is over hyping or more GPT 5.5 which is a real advance @mdancho84
-
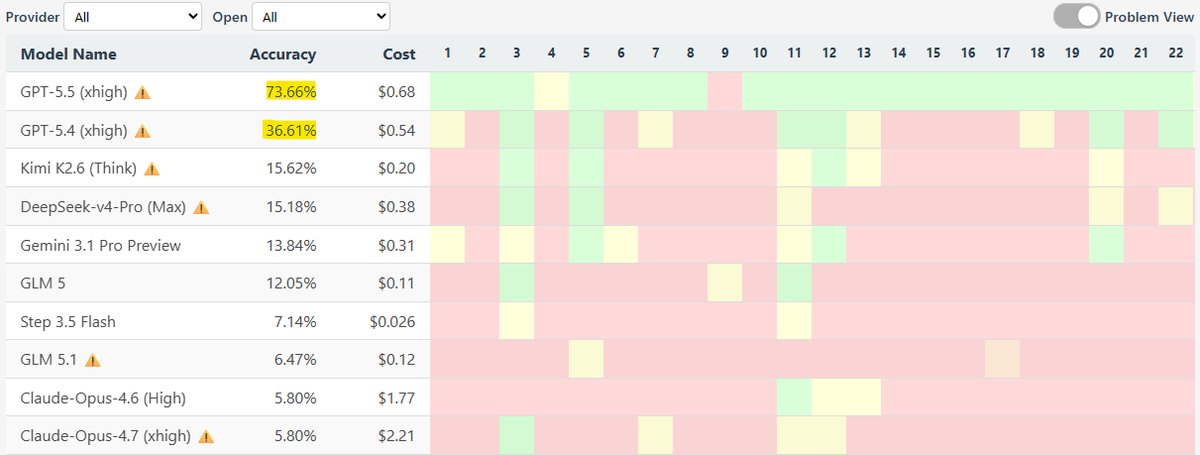
GPT 5.5 Better Fulfills GPT 5 Hype Than Original
By
–
To be fair GPT 5.5 is much closer to what GPT 5 was hyped up to be
-
Robotics Will Be Everywhere in Five Years
By
–
Again check in 5 years from now. We will have robotics all around us https://t.co/93R1anPhCv
— AI (@DeepLearn007) 28 avril 2026Again check in 5 years from now. We will have robotics all around us
-
AI Value Chain Global Acceleration Accelerates Worldwide
By
–
AI value chain is global and only set to accelerate in velocity