Increasing Diversity While Maintaining Accuracy: Text Data Generation with Large Language Models and Human Interventions paper page: https://
huggingface.co/papers/2306.04
140
… Large language models (LLMs) can be used to generate text data for training and evaluating other models. However,
@_akhaliq
-

Generating Diverse Text Data with LLMs and Human Input
By
–
-

Text-only Domain Adaptation for Speech Recognition using Unified Representation
By
–
Text-only Domain Adaptation using Unified Speech-Text Representation in Transducer paper page: https://
huggingface.co/papers/2306.04
076
… Domain adaptation using text-only corpus is challenging in end-to-end(E2E) speech recognition. Adaptation by synthesizing audio from text through TTS is -

Certified Reasoning with Language Models for Sound Step-by-Step Reasoning
By
–
Certified Reasoning with Language Models paper page: https://
huggingface.co/papers/2306.04
031
… Language models often achieve higher accuracy when reasoning step-by-step in complex tasks. However, their reasoning can be unsound, inconsistent, or rely on undesirable prior assumptions. To tackle -

Multi-Hop Reasoning in Language Models via Soft Prompts
By
–
Triggering Multi-Hop Reasoning for Question Answering in Language Models using Soft Prompts and Random Walks paper page: https://
huggingface.co/papers/2306.04
009
… Despite readily memorizing world knowledge about entities, pre-trained language models (LMs) struggle to compose together two or more -

M3IT: Large-Scale Multi-Modal Multilingual Instruction Tuning Dataset
By
–
M3IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning paper page: https://
huggingface.co/papers/2306.04
387
… Instruction tuning has significantly advanced large language models (LLMs) such as ChatGPT, enabling them to align with human instructions across diverse tasks. -
Trending AI News Stories and Papers
By
–
Trending AI news stories + papers https://
open.substack.com/pub/akhaliq/p/
trending-ai-news-stories-papers-07a
… -
Vision Pro and AI/VR Tools: The Next Big Opportunities
By
–
vision pro is the next bug thing ChatGPT is dead I found 1 million AI/VR tools released this week to help you make a bajillion dollars Don’t get left behind
-

InternLM: Multilingual 104B Parameter Language Model Released
By
–
InternLM: A Multilingual Language Model with Progressively Enhanced Capabilities github: https://
github.com/InternLM/Inter
nLM-techreport
… present InternLM, a multilingual foundational language model with 104B parameters. InternLM is pre-trained on a large corpora with 1.6T tokens with a multi-phase -
Recognize Anything: Strong Foundation Model for Image Tagging
By
–
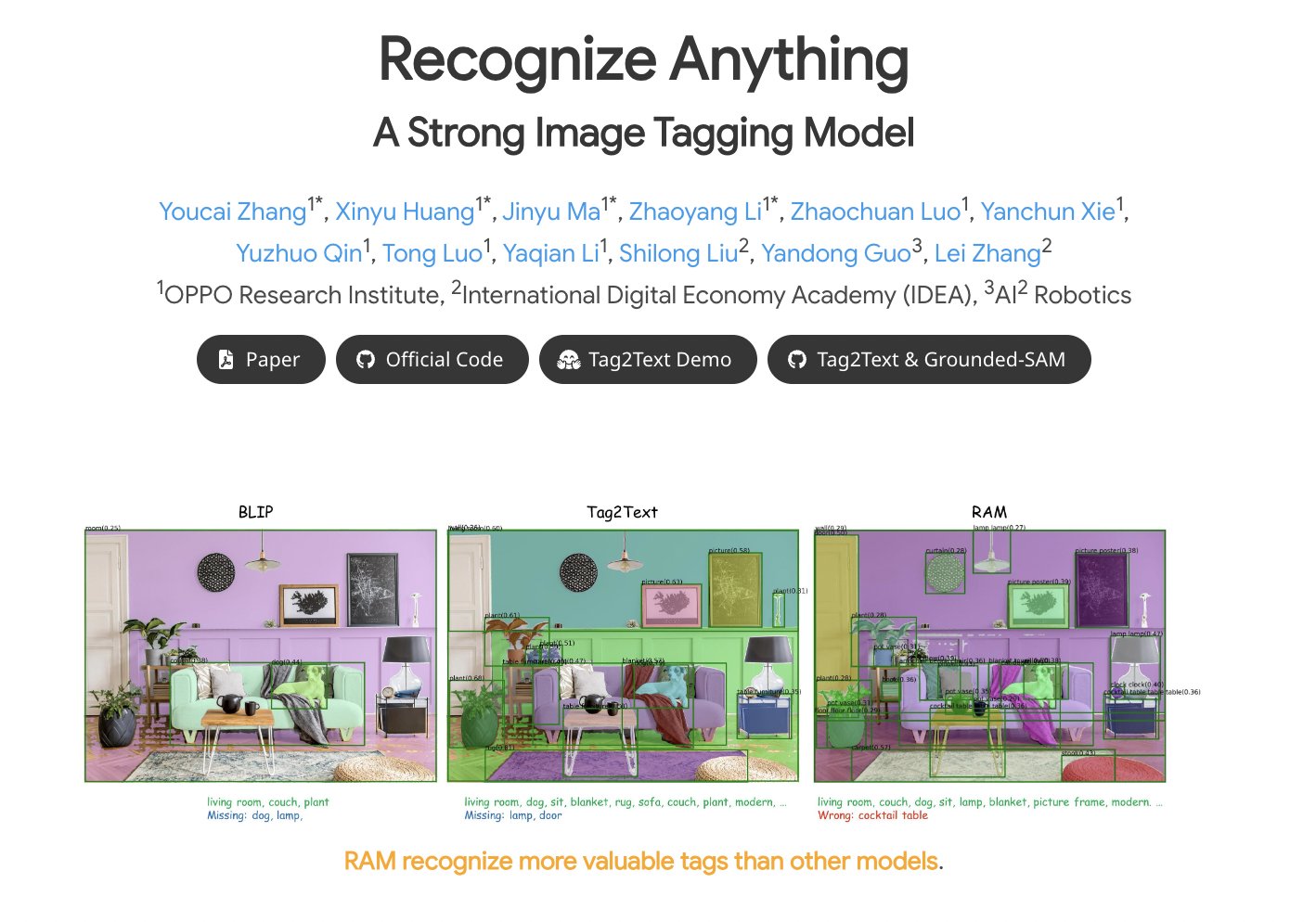
Recognize Anything: A Strong Image Tagging Model paper page: https://
huggingface.co/papers/2306.03
514
…
demo: https://
huggingface.co/spaces/xinyu12
05/Tag2Text
… present the Recognize Anything Model (RAM): a strong foundation model for image tagging. RAM can recognize any common category with high accuracy. RAM introduces a
