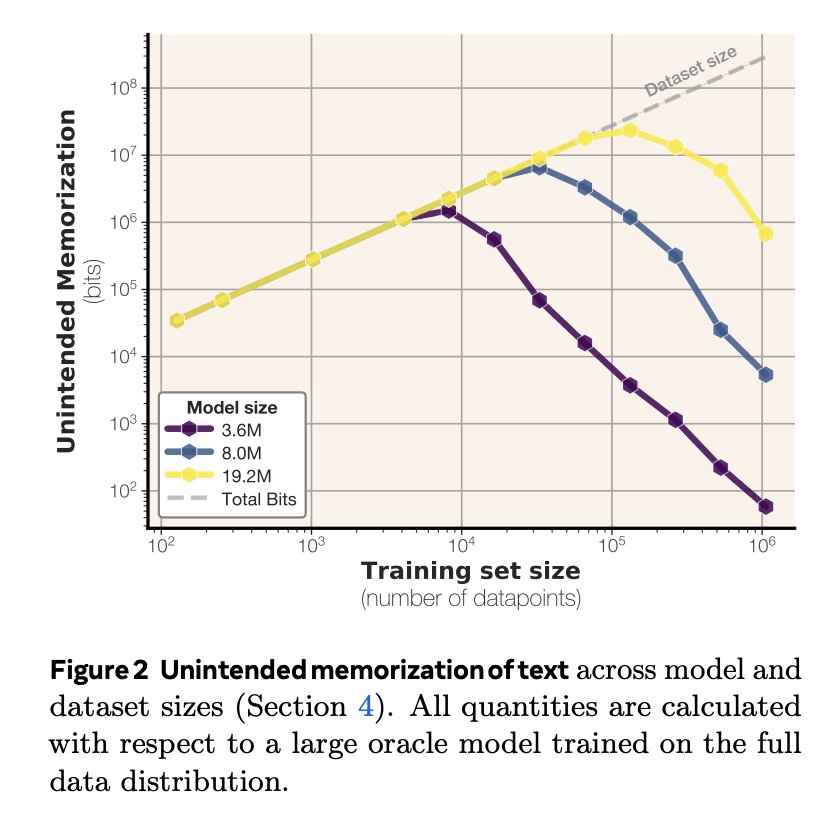
when we train on text data, the curves look different models memorize examples to the extent that they can fit them in their parameters beyond this point, the models discard per-example mem. in favor of shared info (*generalization*) see how the lines start to slope downward:
Model Training: Memorization vs Generalization in Language Models
By
–