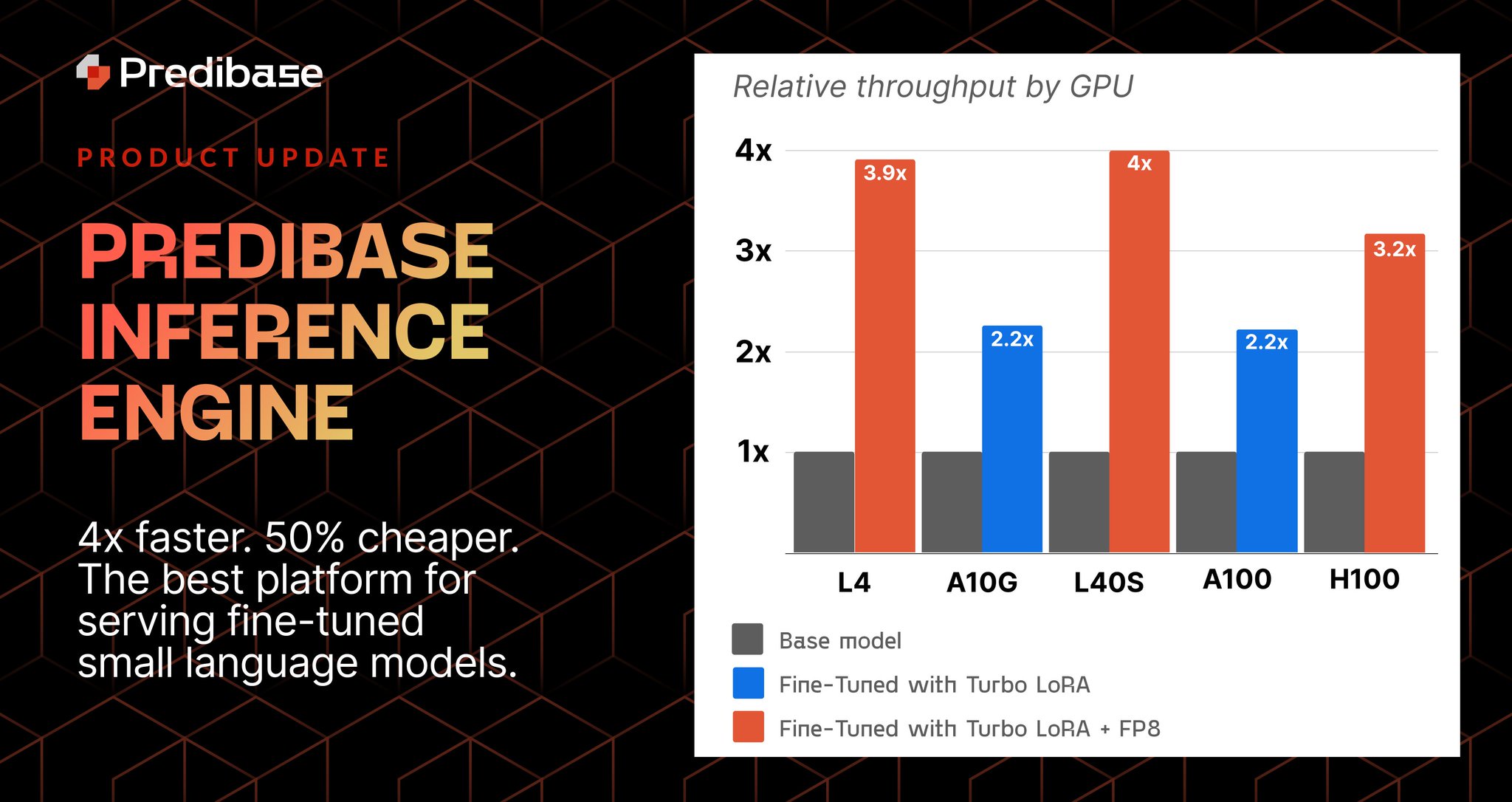
Introducing the Predibase Inference Engine: 4x faster; 50% the cost. The best serving platform for fine-tuned #SLMs! Accelerate deployments with Turbo LoRA, FP8, and GPU autoscaling. Serve 100s of adapters on one GPU. Learn more: https://
pbase.ai/3NmLpwO #AI #infrastructure #LLM
Predibase Inference Engine: 4x Faster, 50% Cost Reduction
By
–