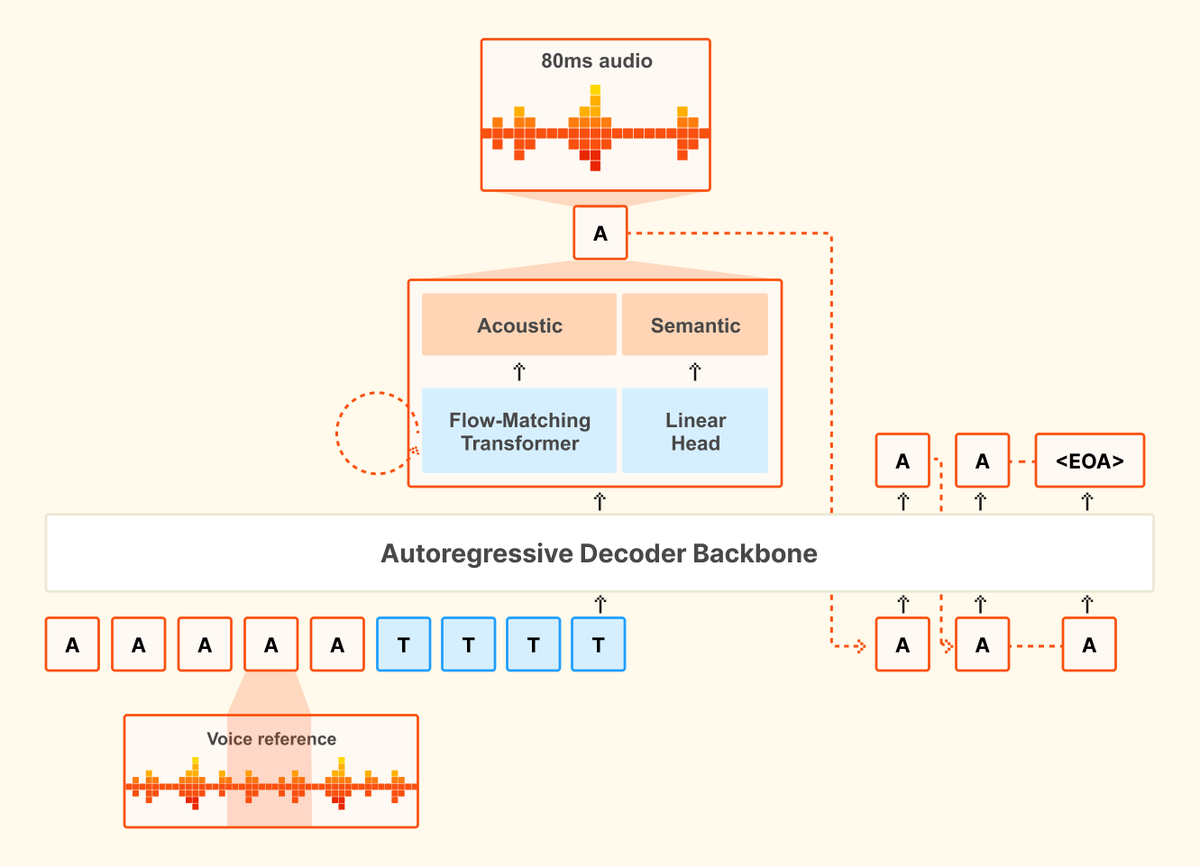
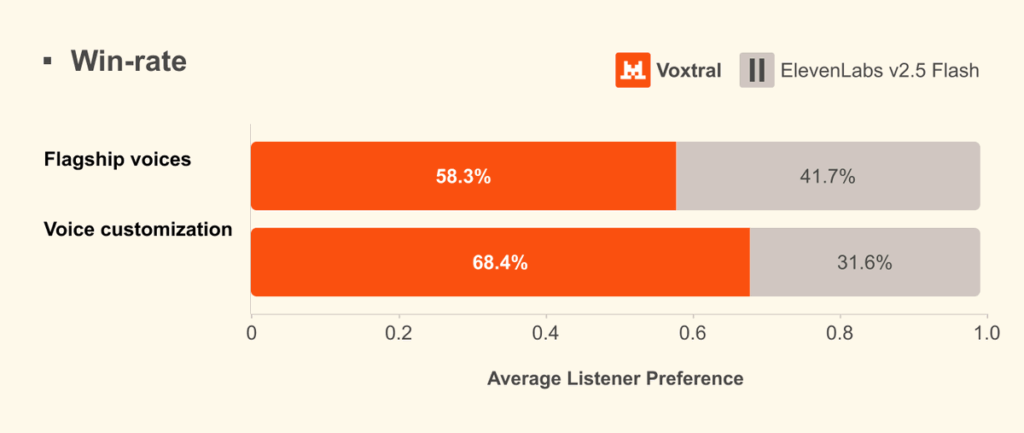
Our first speech model, Voxtral TTS, is out. It delivers SOTA performance while significantly reducing cost compared to existing solutions, and it operates with very low latency. It uses a new architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. We are also releasing a technical report sharing all our training methodology and insights. Much more to come in audio — stay tuned ! Mistral AI (@MistralAI) 🔊Introducing Voxtral TTS: our new frontier open-weight model for natural, expressive, and ultra-fast text-to-speech 🎭Realistic, emotionally expressive speech. 🌍Supports 9 languages and accurately captures diverse dialects. ⚡Very low latency for time-to-first-audio. 🔄Easily adaptable to new voices — https://nitter.net/MistralAI/status/2037183026539483288#m
→ View original post on X — @guillaumelample, 2026-03-26 21:03 UTC