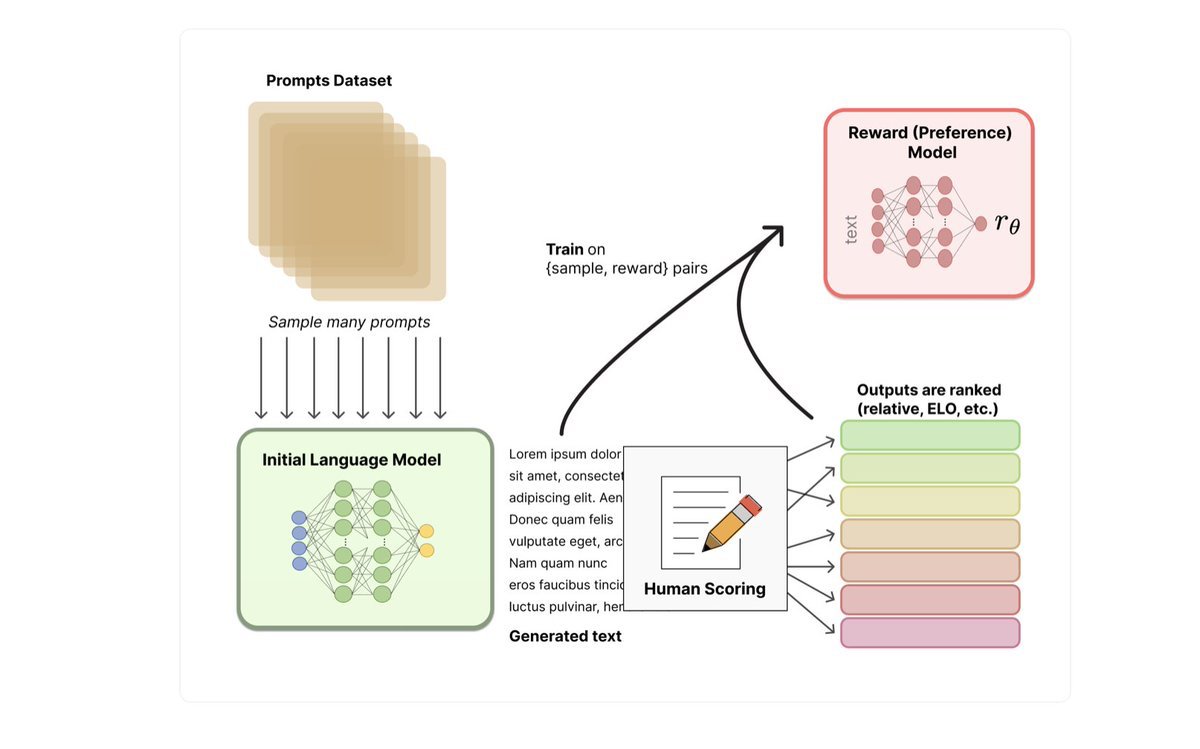
Step2: They used the SFT model to generate multiple responses to a given prompt and the Humans ranks the responses from best to worst. Now we have a labeled dataset, then training a Reward Model will learn how the human would actually rank the responses 7/9
Training Reward Models with Human-Ranked SFT Responses
By
–