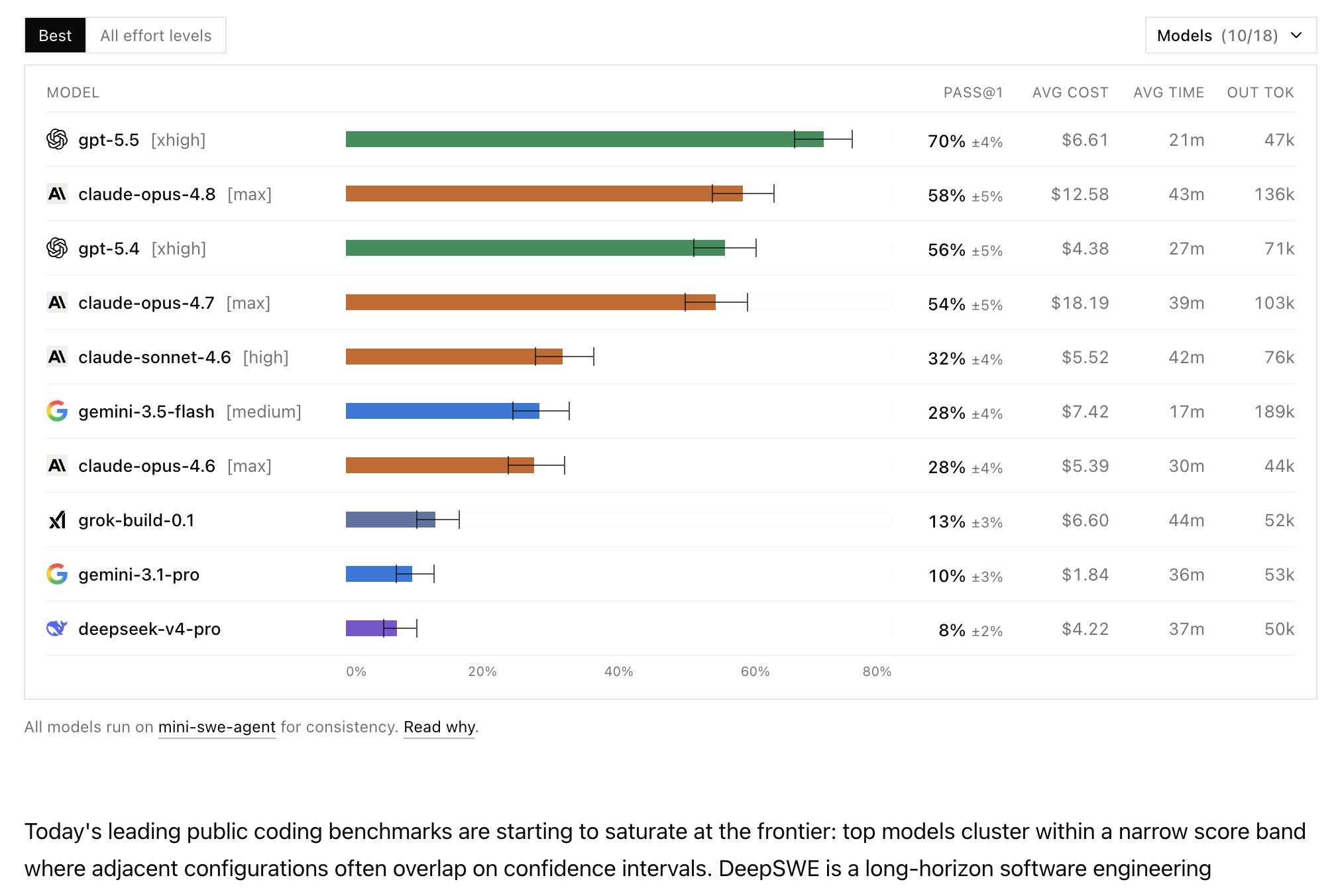

GPT-5.5 is #1 on DeepSWE, a hard long-horizon coding benchmark 70% pass@1 vs 58% for Claude Opus 4.8. And GPT-5.5 gets there with:
~2x faster runs
~1/2 the cost
~1/3 the output tokens Literally, better intelligence per dollar, per minute, per task.