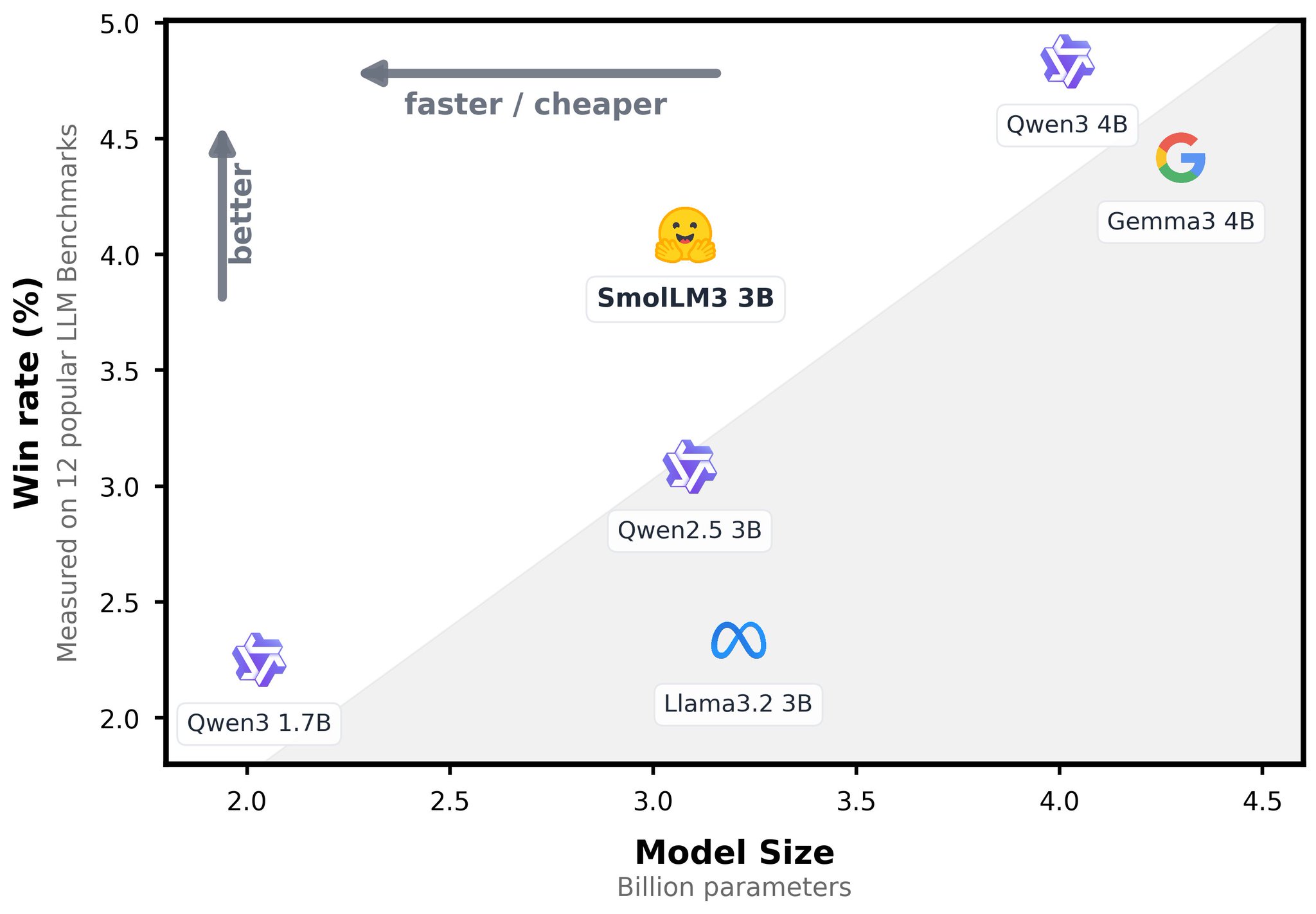
Qwen left a hole in the Pareto frontier of optimal performance for a given size… So we just filled it: introducing SmolLM3-3B I helped the SmolLM team on the "make it agentic" part, by post-training the model on agent traces with @akseljoonas
: the model is now also on
SmolLM3-3B fills Qwen’s Pareto gap via agentic post-training
By
–