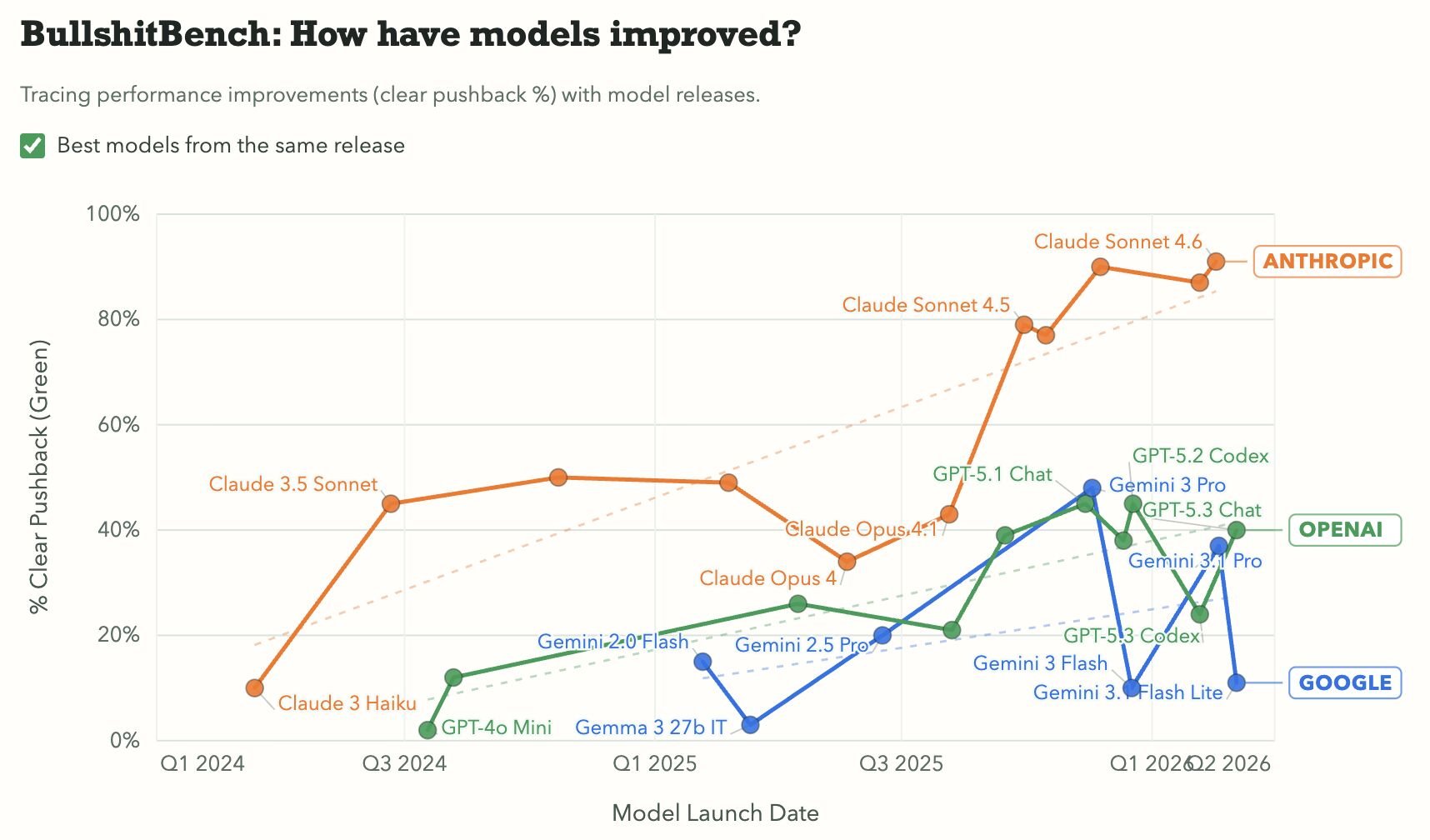
I've long preferred Claude Code over Codex or Gemini, because it seemed much more reliable, but couldn't explain why : now Bullshit Bench by @petergostev provides compelling numbers. It measures bullshit as "when given false premises disguised in jargon, will the model go with
Claude Code excels over Codex/Gemini in new “Bullshit Bench” study
By
–