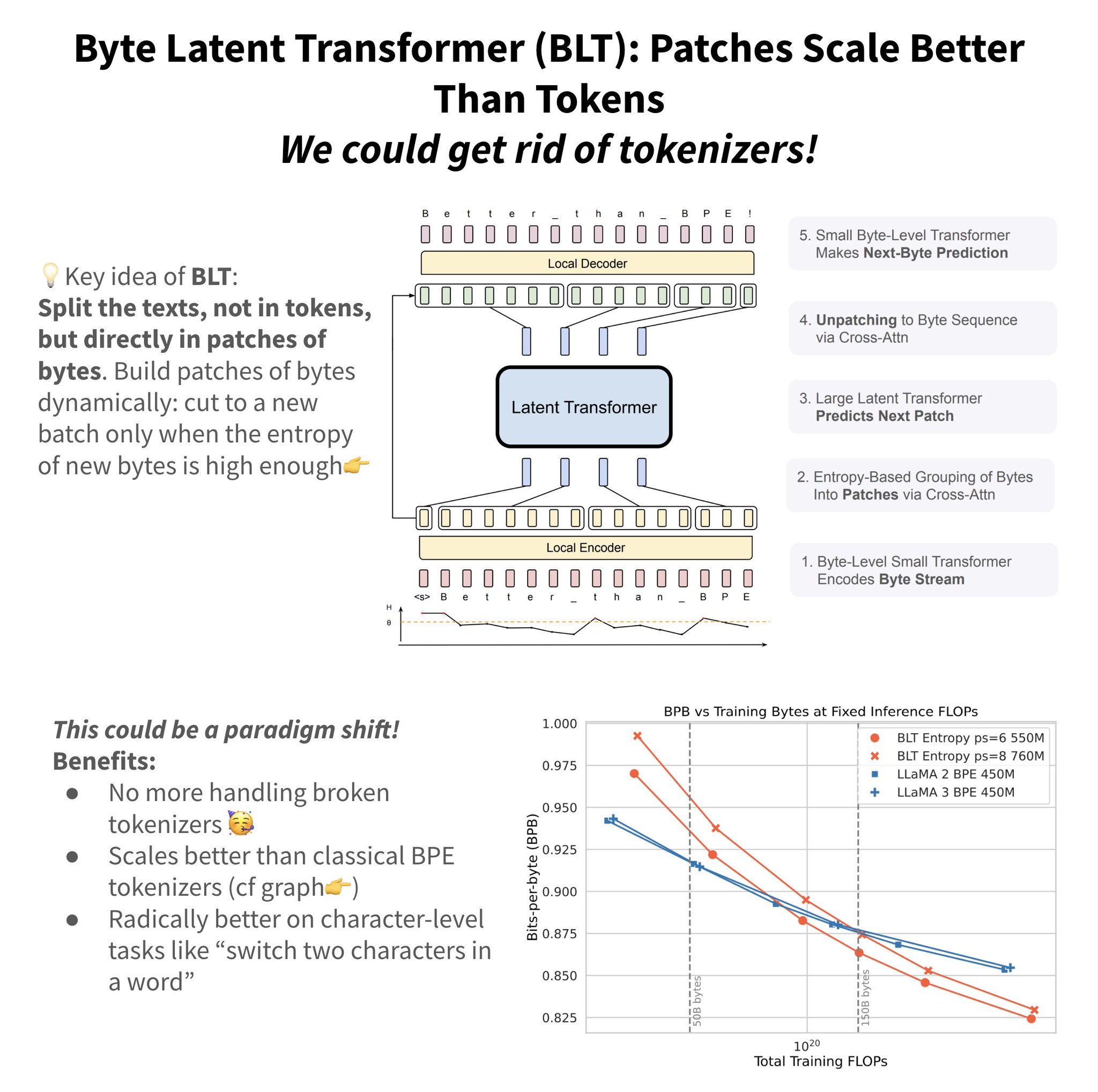
Potential paradigm shift in LLMs: new paper by @AIatMeta shows that we can get rid of tokenizers! Current LLMs process text by first splitting it into tokens. They use a module named "tokenizer", that -spl-it-s- th-e- te-xt- in-to- arbitrary tokens depending on a fixed