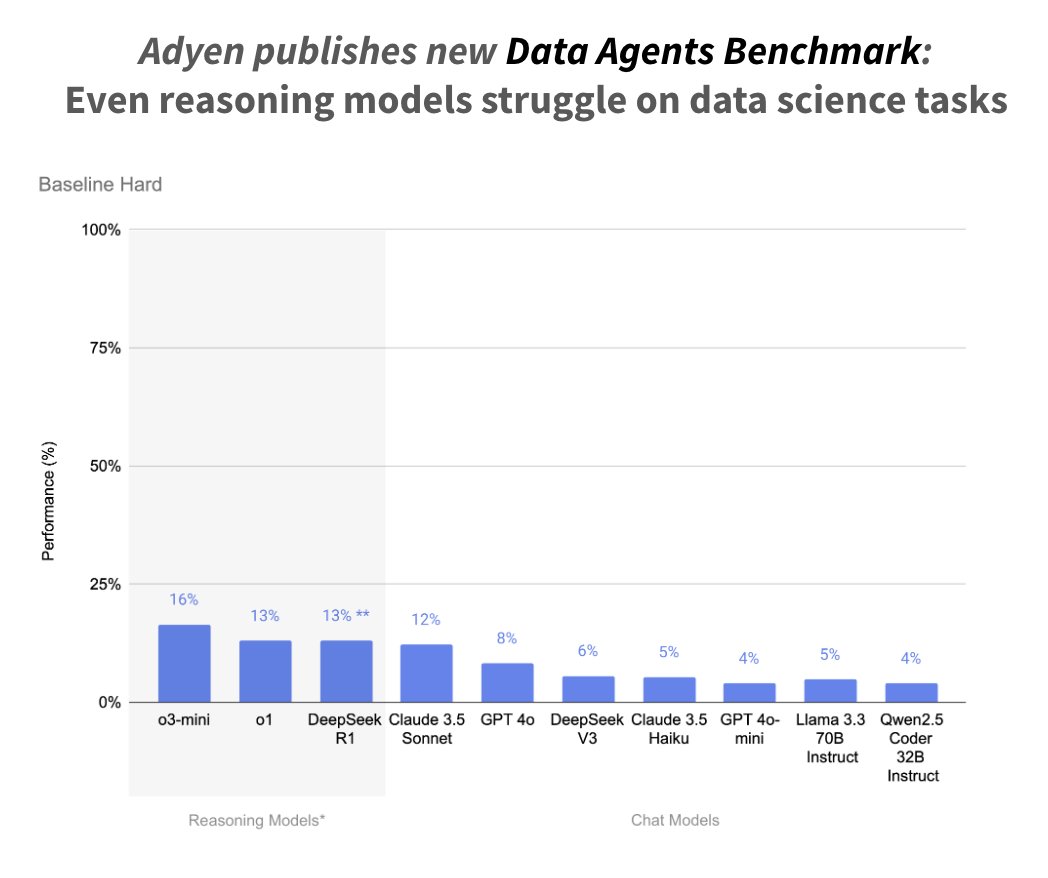
Adyen's new Data Agents Benchmark shows that DeepSeek-R1 struggles on data science task! How well do reasoning models perform on agentic tasks? Until now, all indicators seemed to show that they worked really well. On our recent reproduction of Deep Search, OpenAI's o1 was
Performance evaluation of reasoning models on agentic data science tasks
By
–