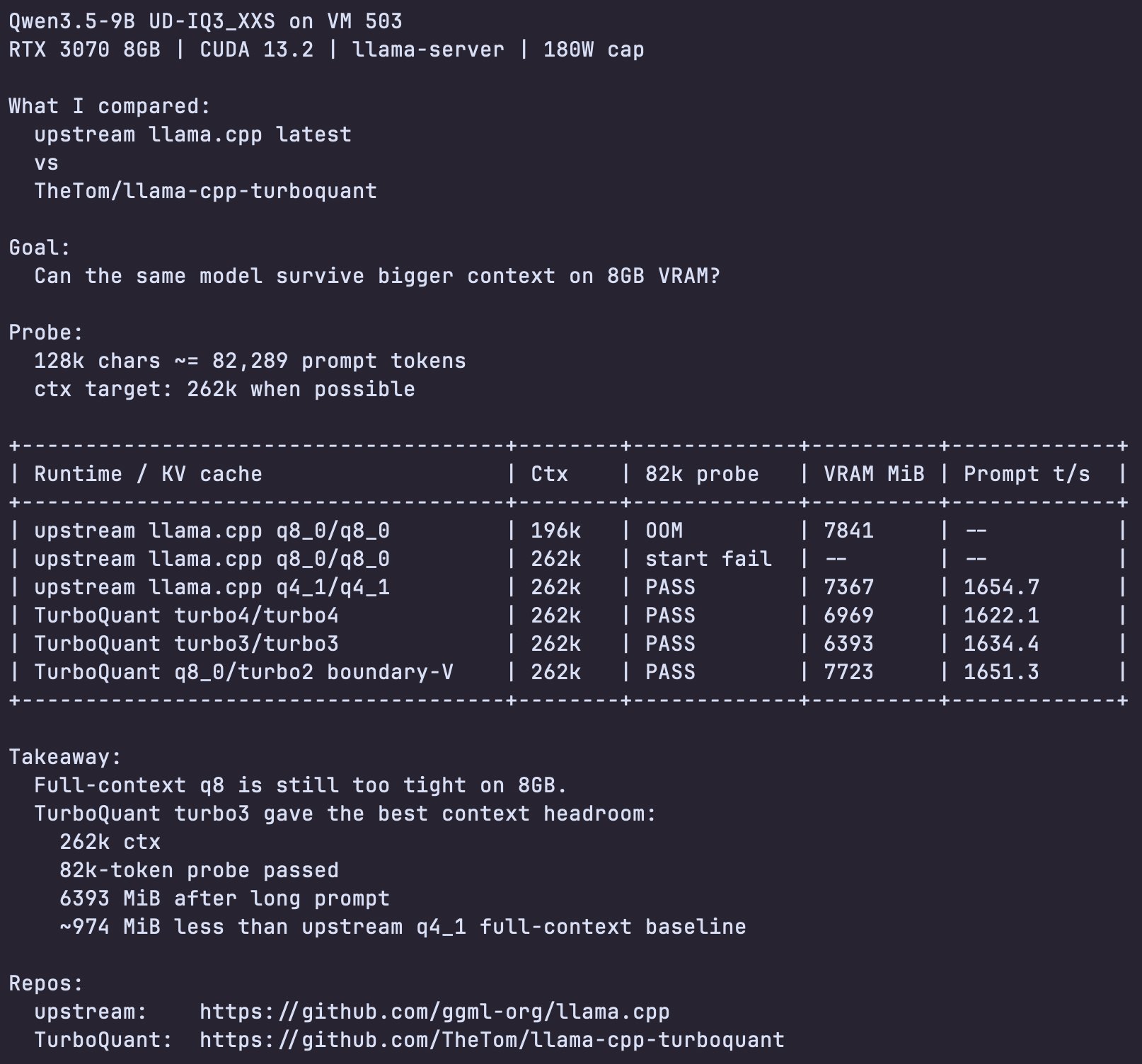
Benchmarked the same Qwen3.5 9B UD-IQ3_XXS GGUF on an RTX 3070 8GB using – Latest upstream llama.cpp VS – TheTom's TurboQuant llama.cpp fork TurboQuant allowed me to reach full context length without OOM, more in the screenshot below
Qwen3.5 9B benchmarked: TurboQuant avoids OOM at full context
By
–