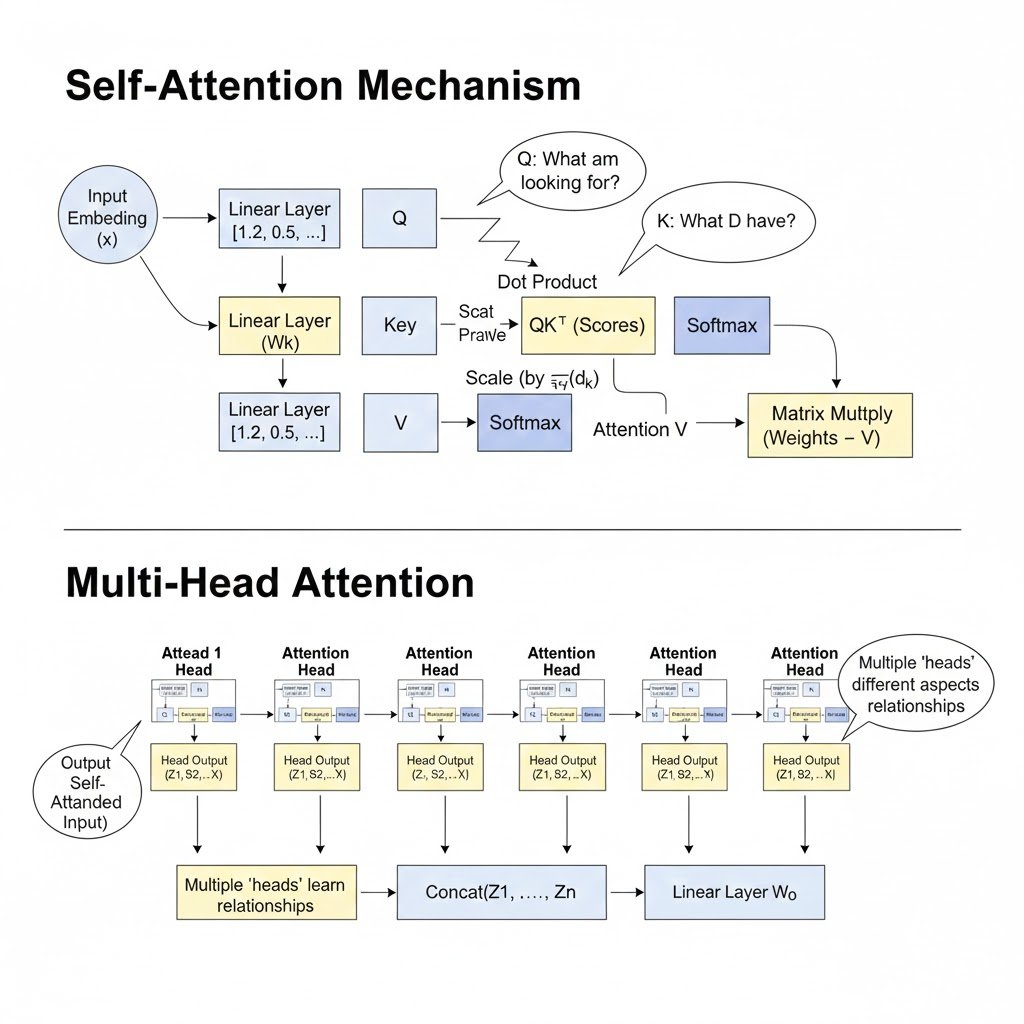
encoder – multi head self attention mechanism with feed forward neural nets multi head attention learns the different relations between words compared to self attention which leans to pay attention to each word in the context
Multi-Head Self Attention: Key Mechanism in Transformer Models
By
–