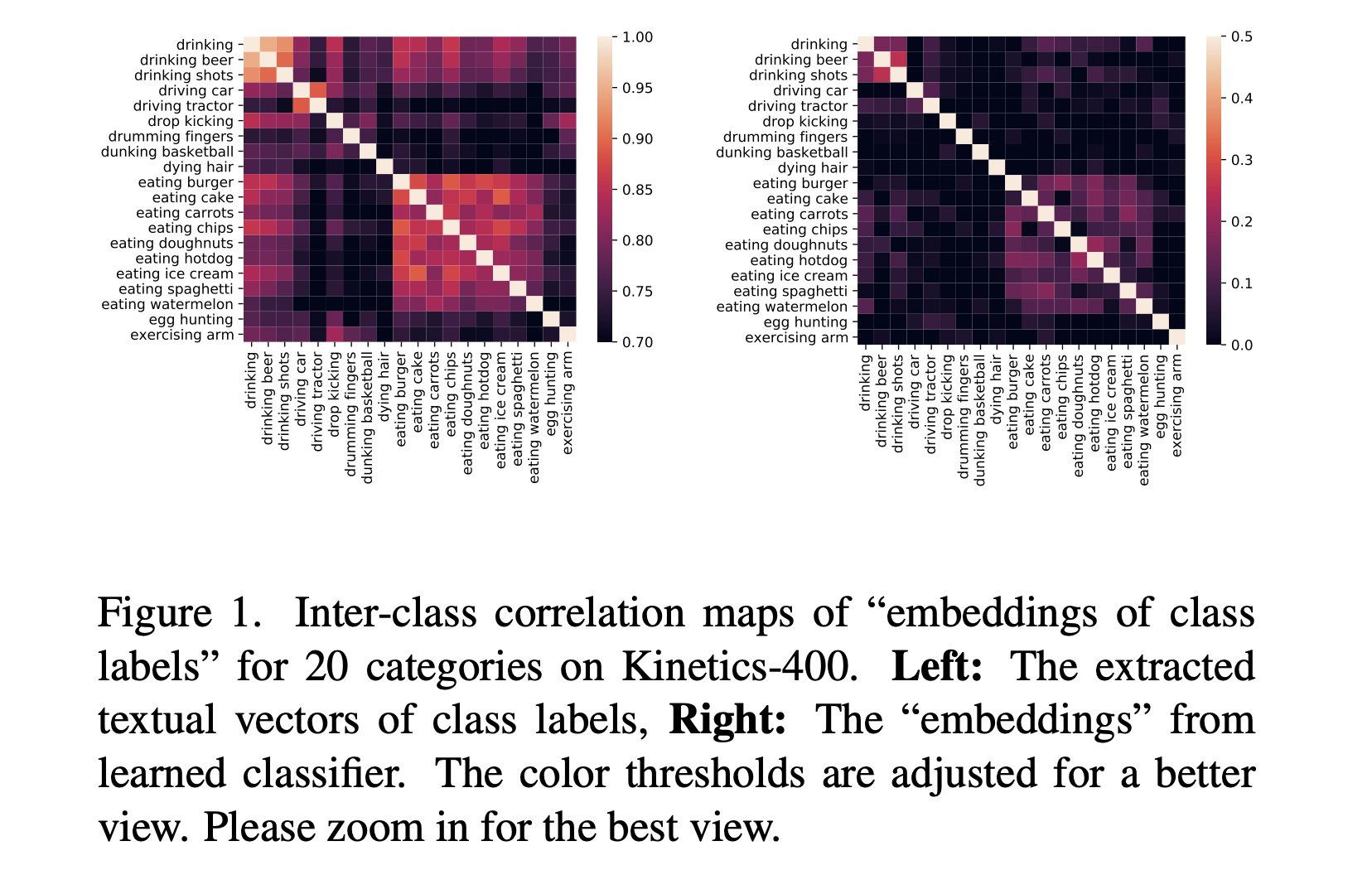
We use pre-trained vision-language models to improve video classification, achieving SOTA performance on Kinetics-400 and surpassing previous methods by 20-50% on five popular video datasets. #AAAI2023 Github: https://
github.com/whwu95/Text4Vis
Vision-Language Models Achieve SOTA Video Classification Performance
By
–