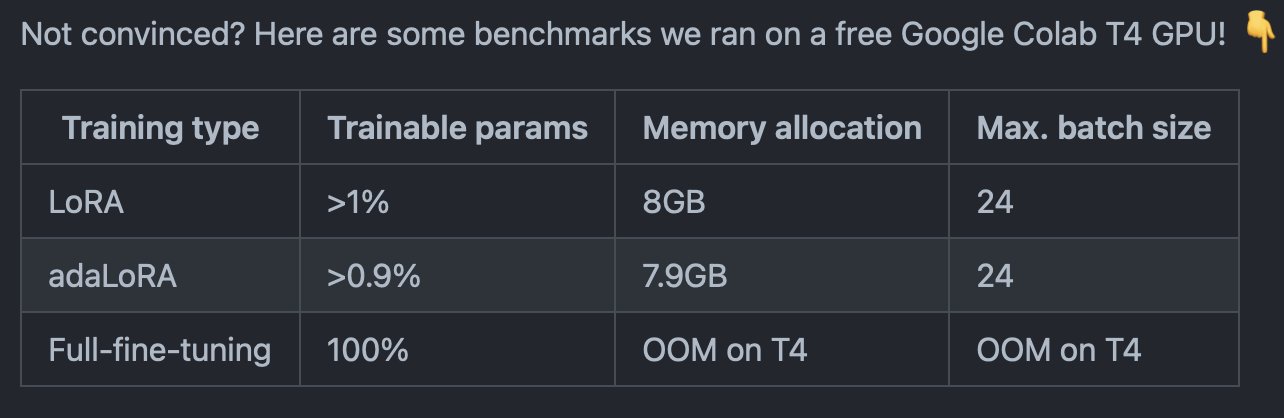
For a full fine-tuning run, on a @GoogleColab T4 GPU, Whisper large model throws an OOM. Through PEFT, we are not just able to fine-tune the Whisper large checkpoint but also squeeze in a batch size of 24 in < 8GB VRAM on a consumer GPU
PEFT enables Whisper large fine-tuning on consumer GPUs efficiently
By
–