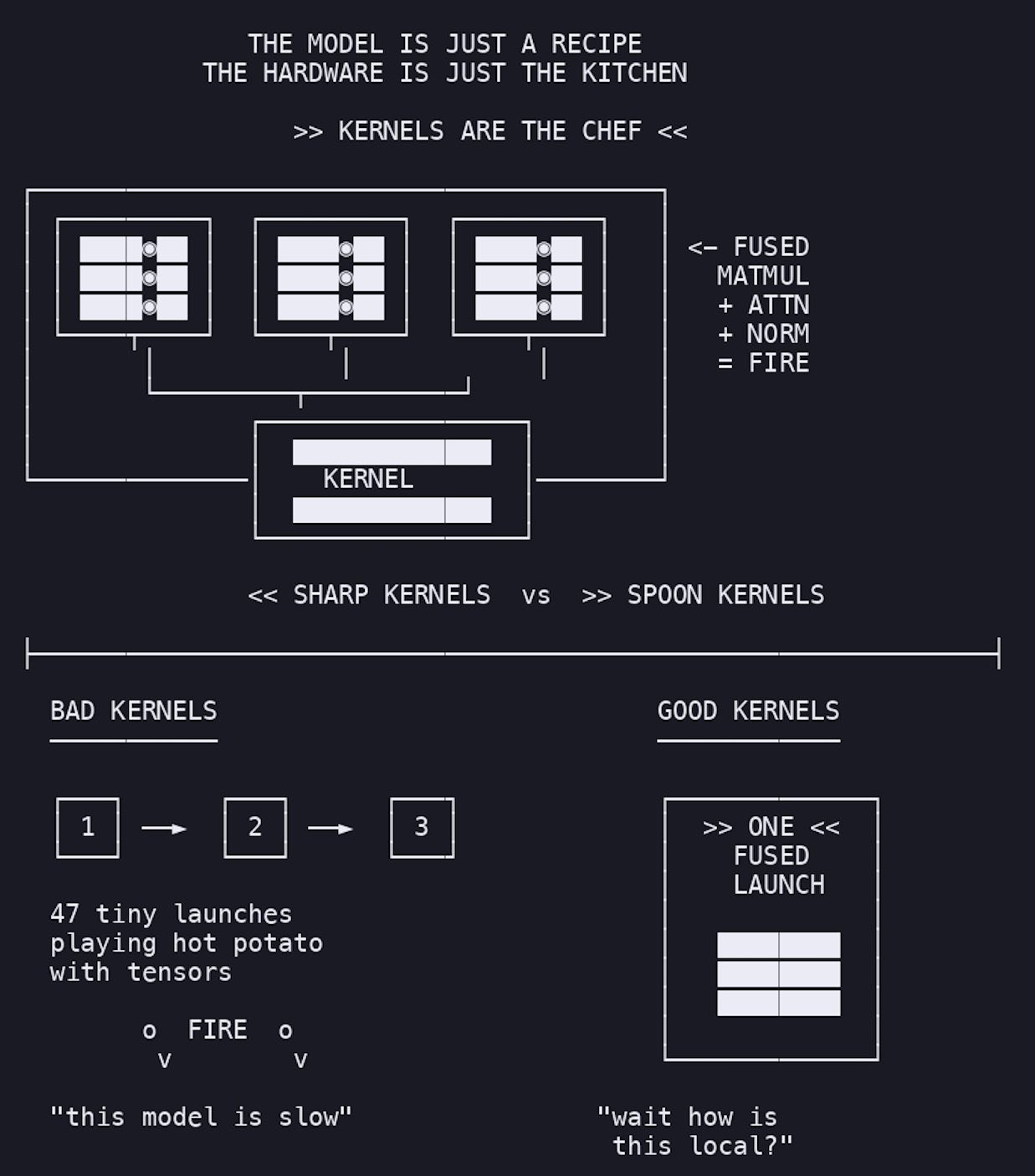
You don’t “run a model”
You run Kernels The model is just a graph The Inference Engine is scheduler / optimizer / executor But the actual work? That happens in the Kernels – MatMul Kernels
– Attention Kernels
– RMSNorm Kernels
– KV cache Kernels
– Quantized linear Kernels
–
Kernels Are the Actual Work in Model Inference
By
–