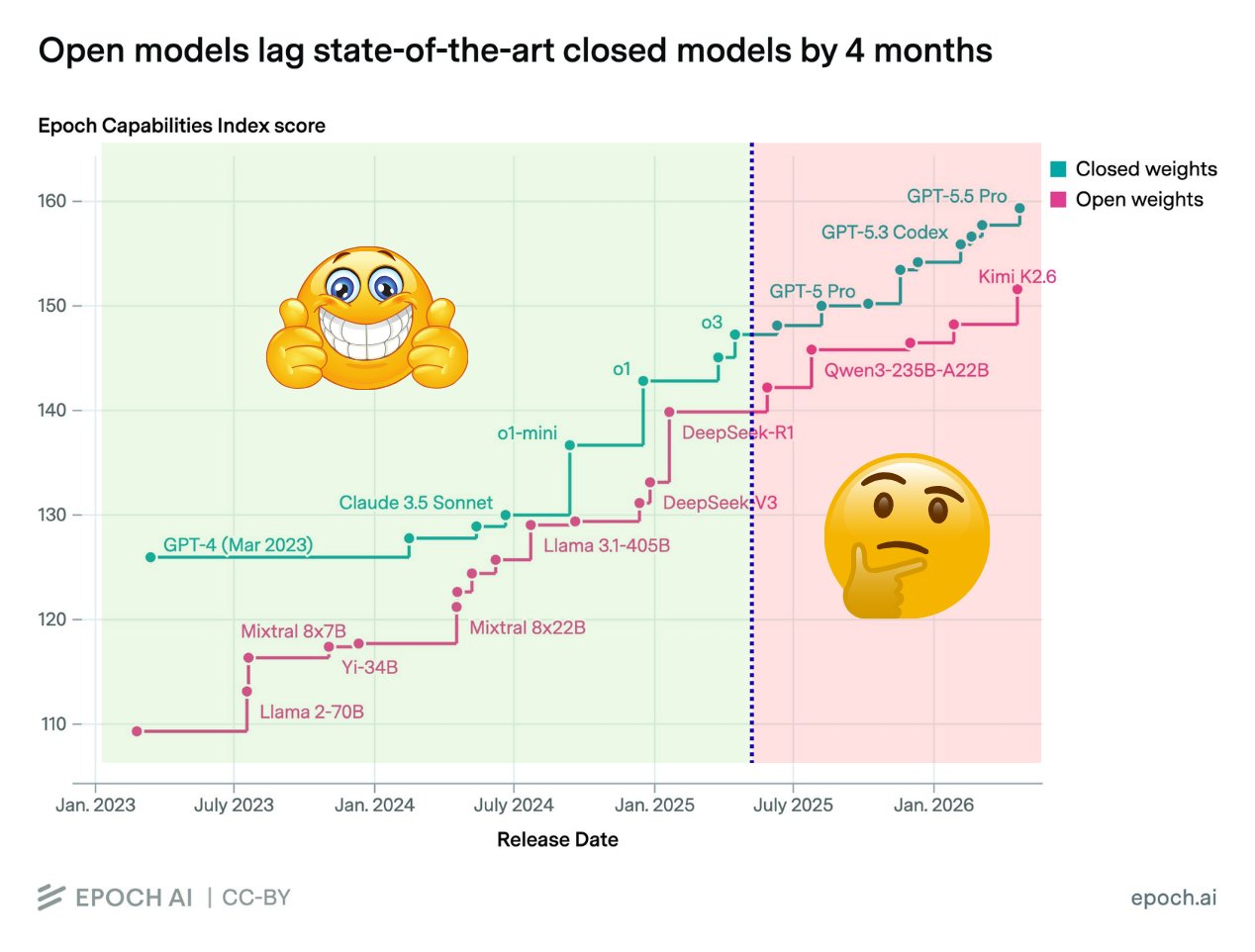
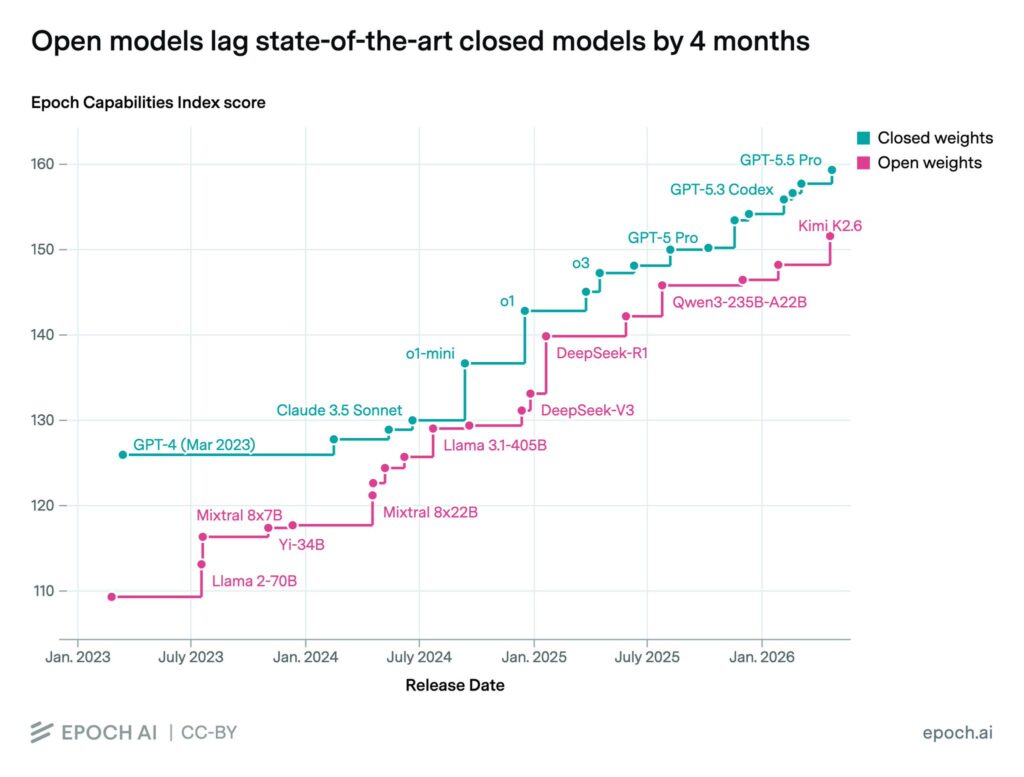
My personal vibes based opinion on this gap – at DeepSeek R1 level I believe this was real – o1 and r1 were not that far apart. From o3 onwards, I think there's something fishy going on with the benchmarks. Open models are not bad and certainly getting better, but the utility