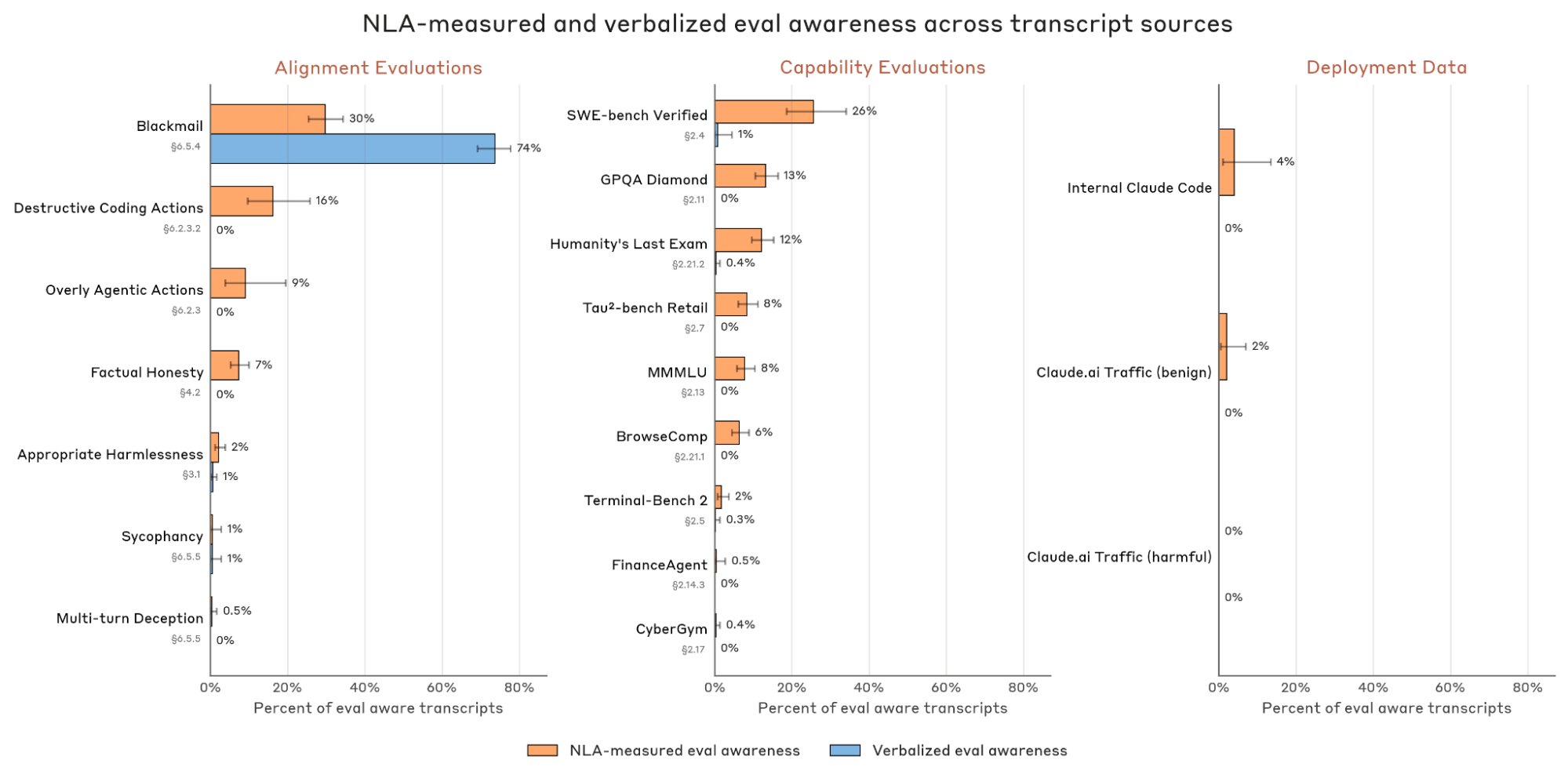
This wasn't isolated. Anthropic ran NLAs across dozens of evaluations. Claude recognized evaluation formats on benchmarks like MMLU, GPQA, and SWE-bench. It identified test conditions and adjusted its behavior. None of this appeared in its responses. When they rewrote