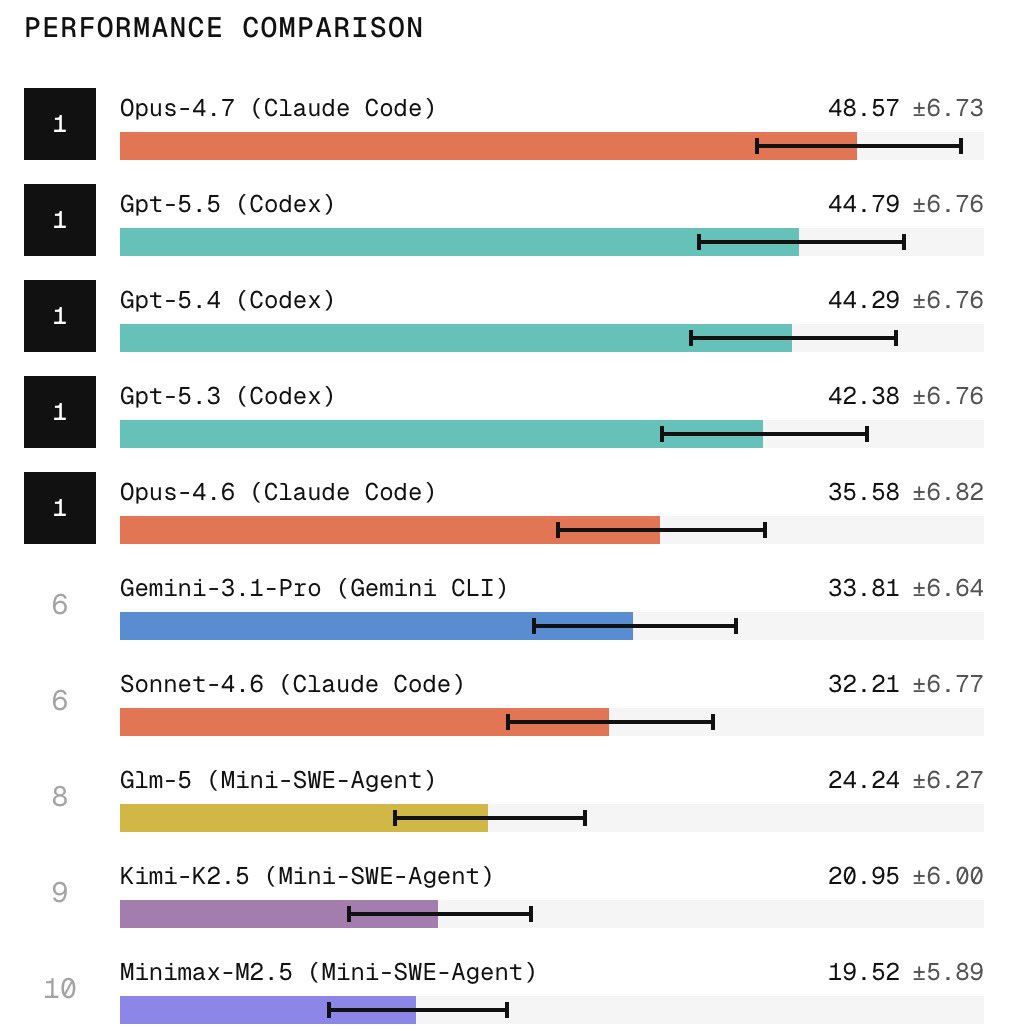

Scale AI published SWE Atlas Refactoring Leaderboard, a new benchmark that evaluates agent capabilities of restructuring the code. > It requires agents to produce twice as much lines of code than SWE Bench Pro. > Claude Code with Opus 4.7 tops the leaderboard followed by