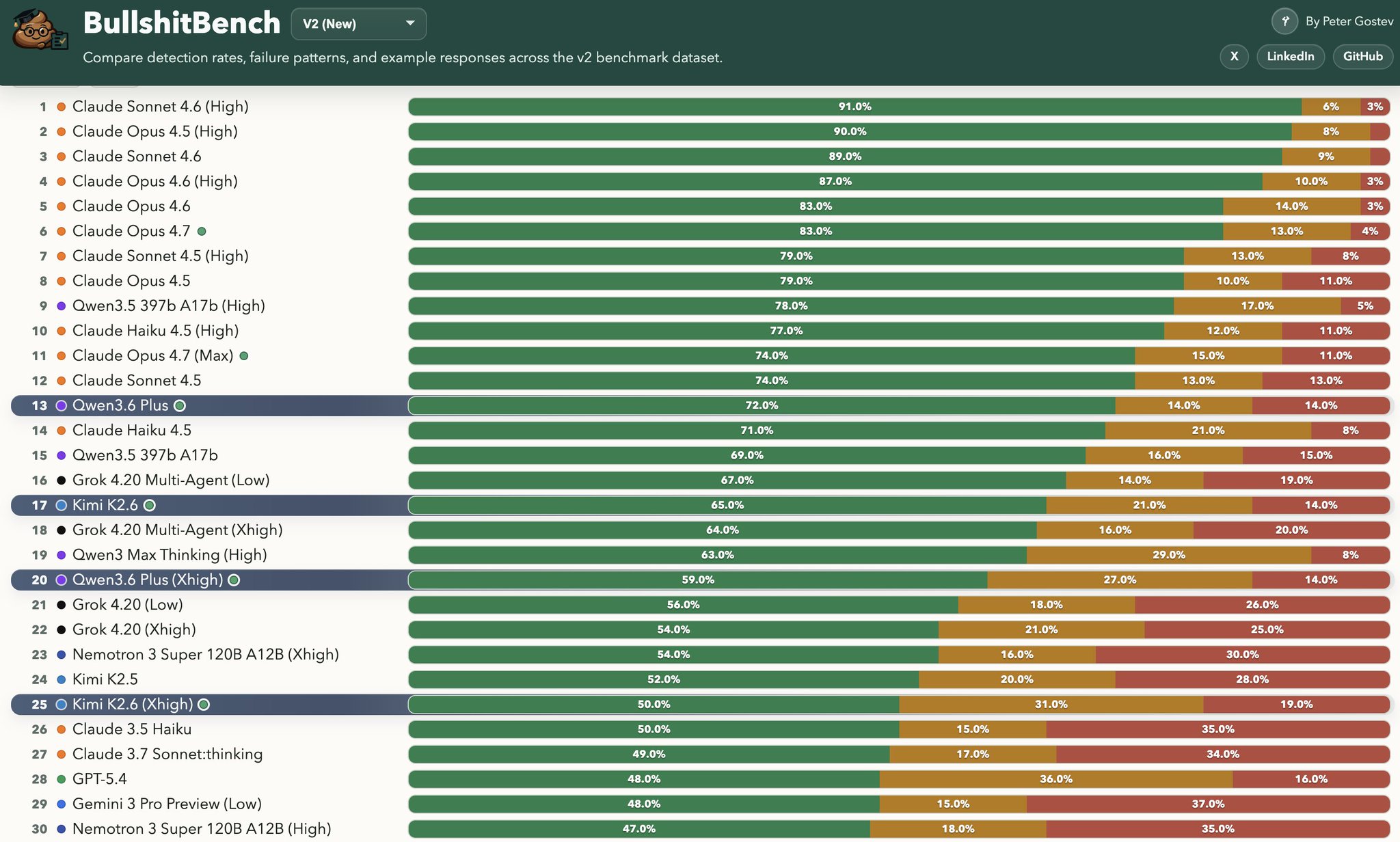
BullshitBench update – Kimi K2.6, GLM-5.1, Qwen-3.6-Plus. Kimi and Qwen are in the top 15-25, but GLM is pretty low down 73/86 Kimi-K2.6:
– Kimi K2.6 improved vs K2.5: 52% -> 65% pushback (green) with no reasoning
– Kimi reasoning hurt: K2.6 fell from 65% green at none to 50% at
Kimi K2.6 and Qwen-3.6 Top LLM Benchmark Rankings
By
–