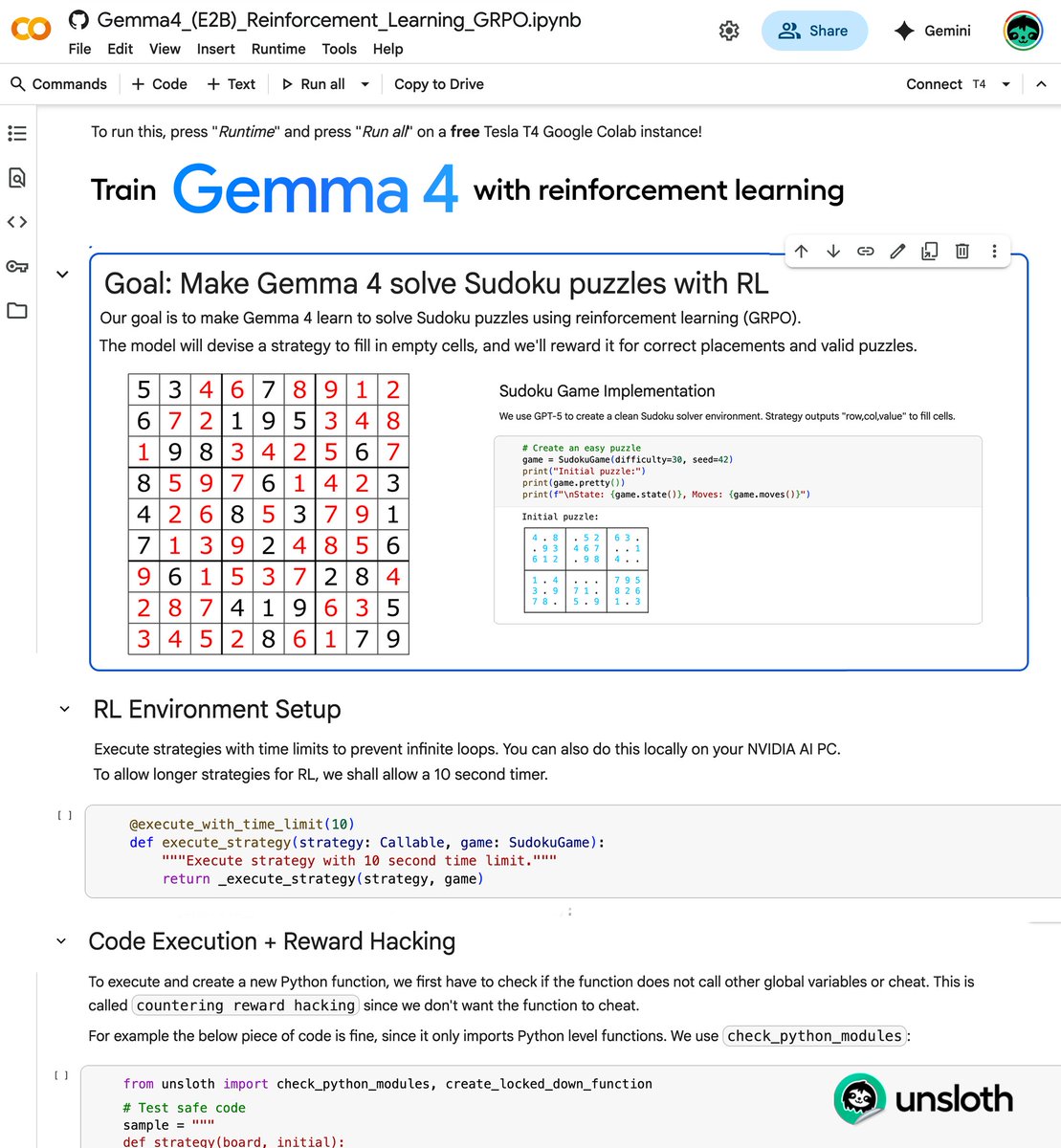
Train Gemma 4 with reinforcement learning! Unsloth just added GRPO support for Gemma 4. You can now RL fine-tune Google's latest model on a consumer GPU. The example notebook teaches Gemma 4 to solve Sudoku puzzles autonomously. The model learns through trial and error with
Unsloth Enables GRPO Training for Gemma 4 on Consumer GPUs
By
–