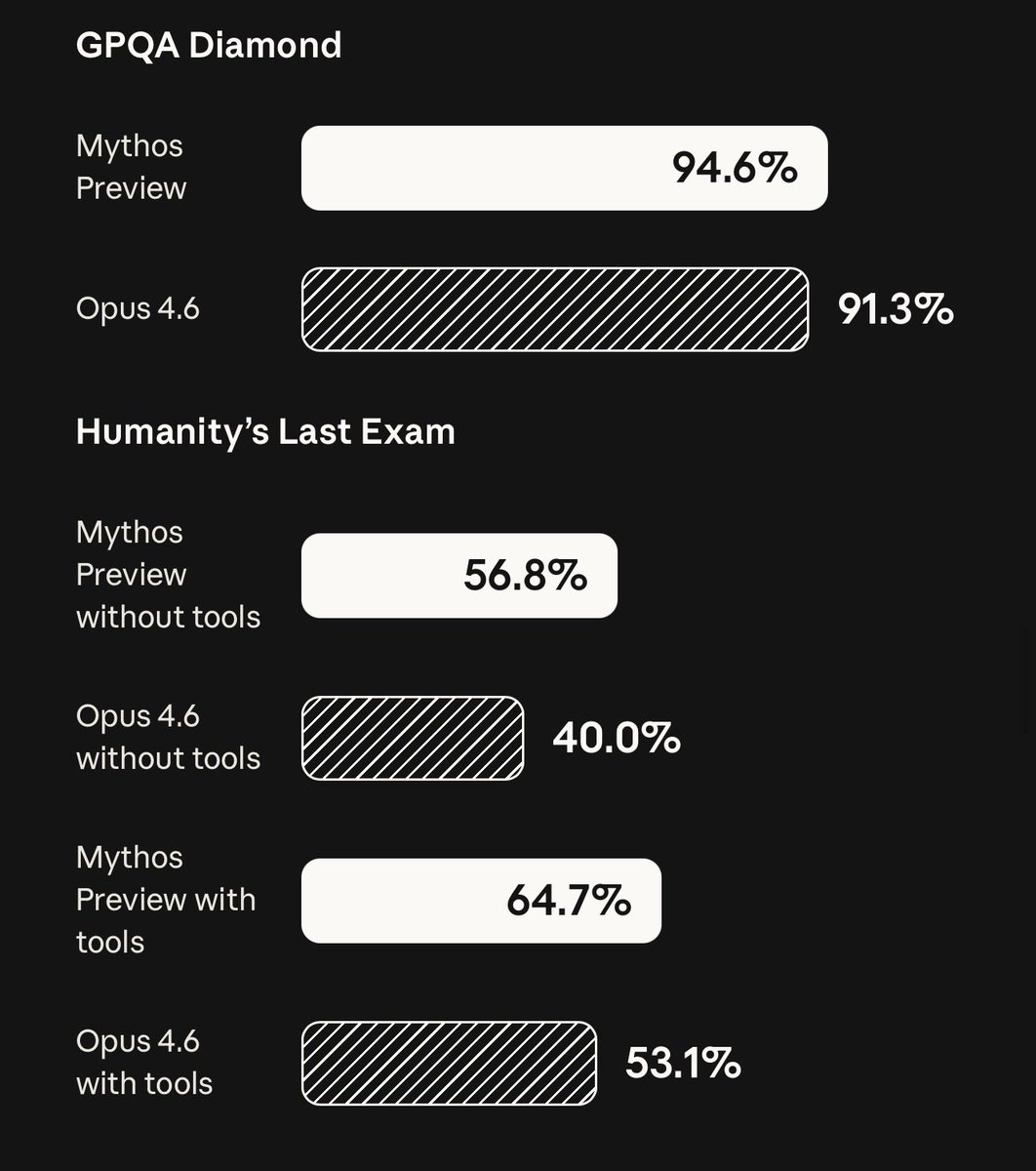
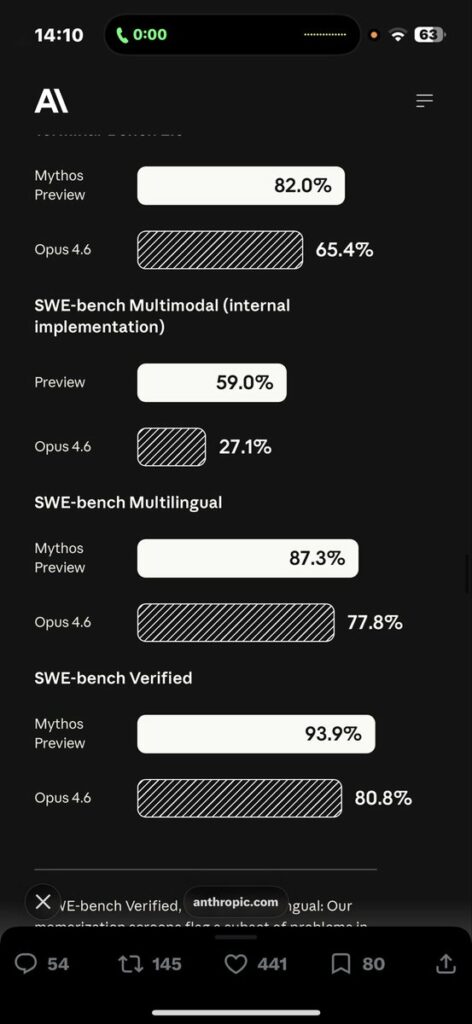
🚨 ANTHROPIC JUST BROKE SWE-BENCH PRO WITH CLAUDE MYTHOS 🚨 Anthropic just dropped the numbers for their unreleased "Claude Mythos Preview" and the coding leap is almost incomprehensible. This model is so powerful at finding exploits that they are keeping it strictly locked down for critical infrastructure partners. Anthropic explicitly stated: "We’ve used Claude Mythos to demonstrate thousands of zero day vulnerabilities." Look at the absolute destruction of these benchmarks compared to Opus 4.6: • SWE-Bench Pro: 77.8% (Destroying Opus 4.6 at 53.4%) • Terminal-Bench 2.0: 82.0% (Up from 65.4%) • SWE-Bench Verified: 93.9% • SWE-Bench Multimodal: 59.0% (More than double Opus 4.6's 27.1%) • Humanity's Last Exam (with tools): 64.7% (Up from 53.1%) • GPQA Diamond: 94.6% A nearly 25-point jump in SWE-Bench Pro in a single generation. And we’re in *checks notes* April..
→ View original post on X — @scobleizer, 2026-04-07 18:20 UTC