.@GoogleGemma 4 31B is up to 2.7X faster on RTX using llama.cpp. Thanks to @ggerganov for working with us to make this model fast.
→ View original post on X — @huggingface, 2026-04-02 19:30 UTC
By
–
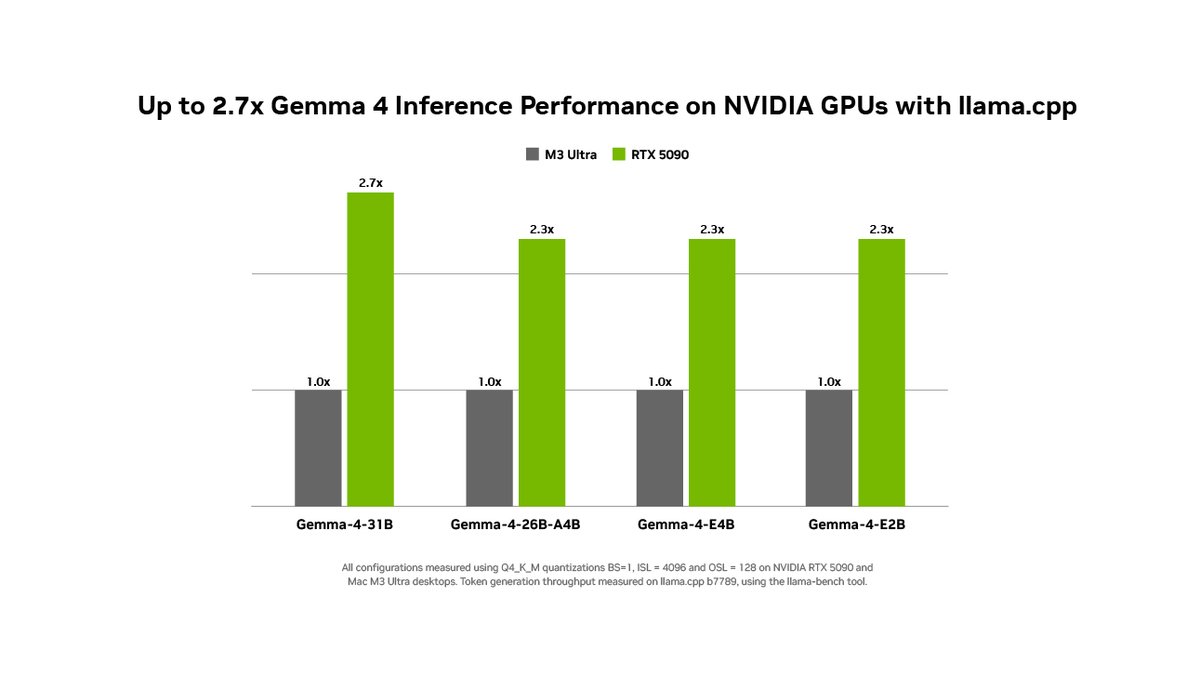
.@GoogleGemma 4 31B is up to 2.7X faster on RTX using llama.cpp. Thanks to @ggerganov for working with us to make this model fast.
→ View original post on X — @huggingface, 2026-04-02 19:30 UTC