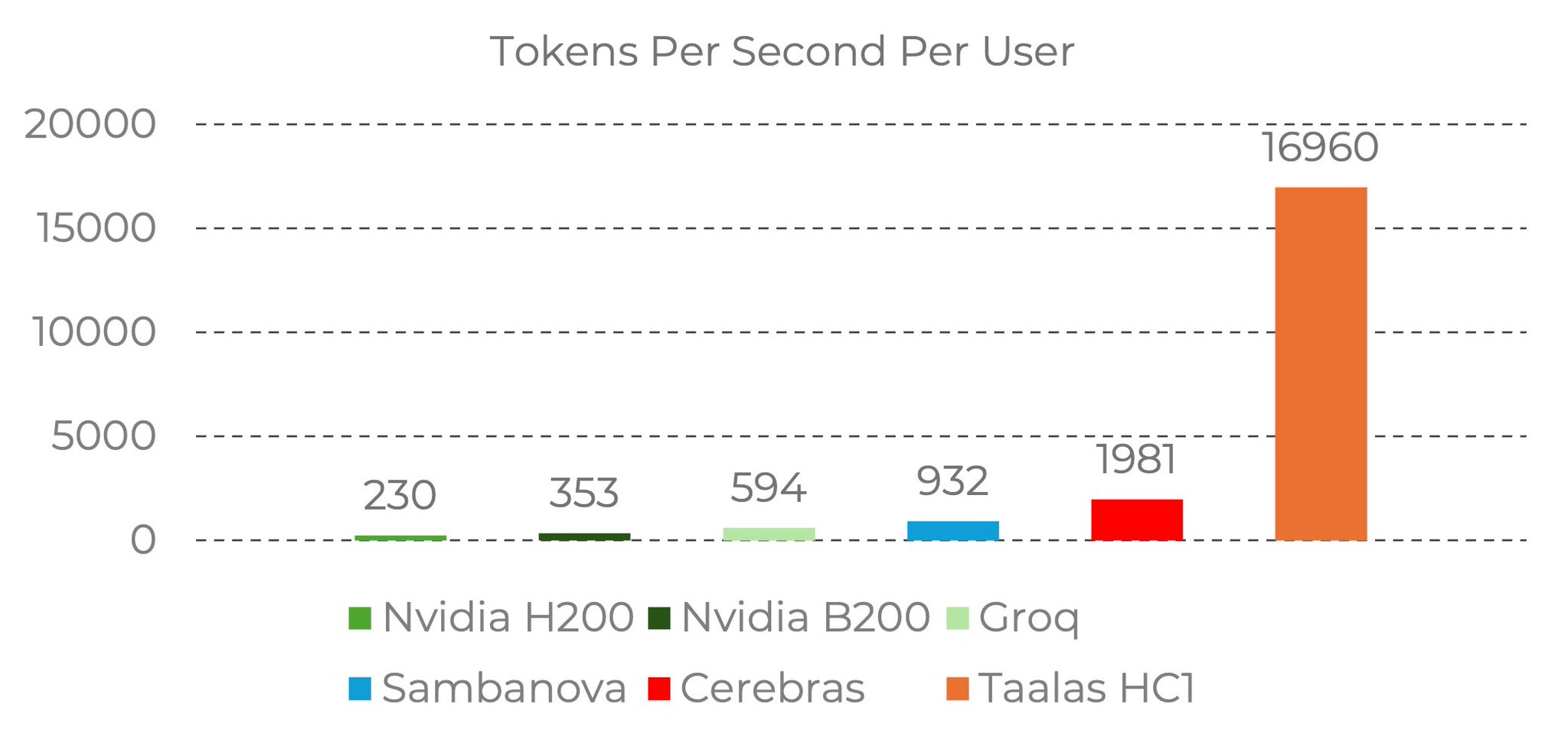
Custom hardware from Taalas runs Llama-3.1-8B, at 17k tokens per second
17k Absolutely insane (For the record Cerebras is crazy good and they're at 2k on the same model)
And latency is very low too! Their chatbot is here: https://
chatjimmy.ai It's genuinely a eerie
Custom Taalas hardware runs Llama-3.1-8B at 17k tokens per second
By
–