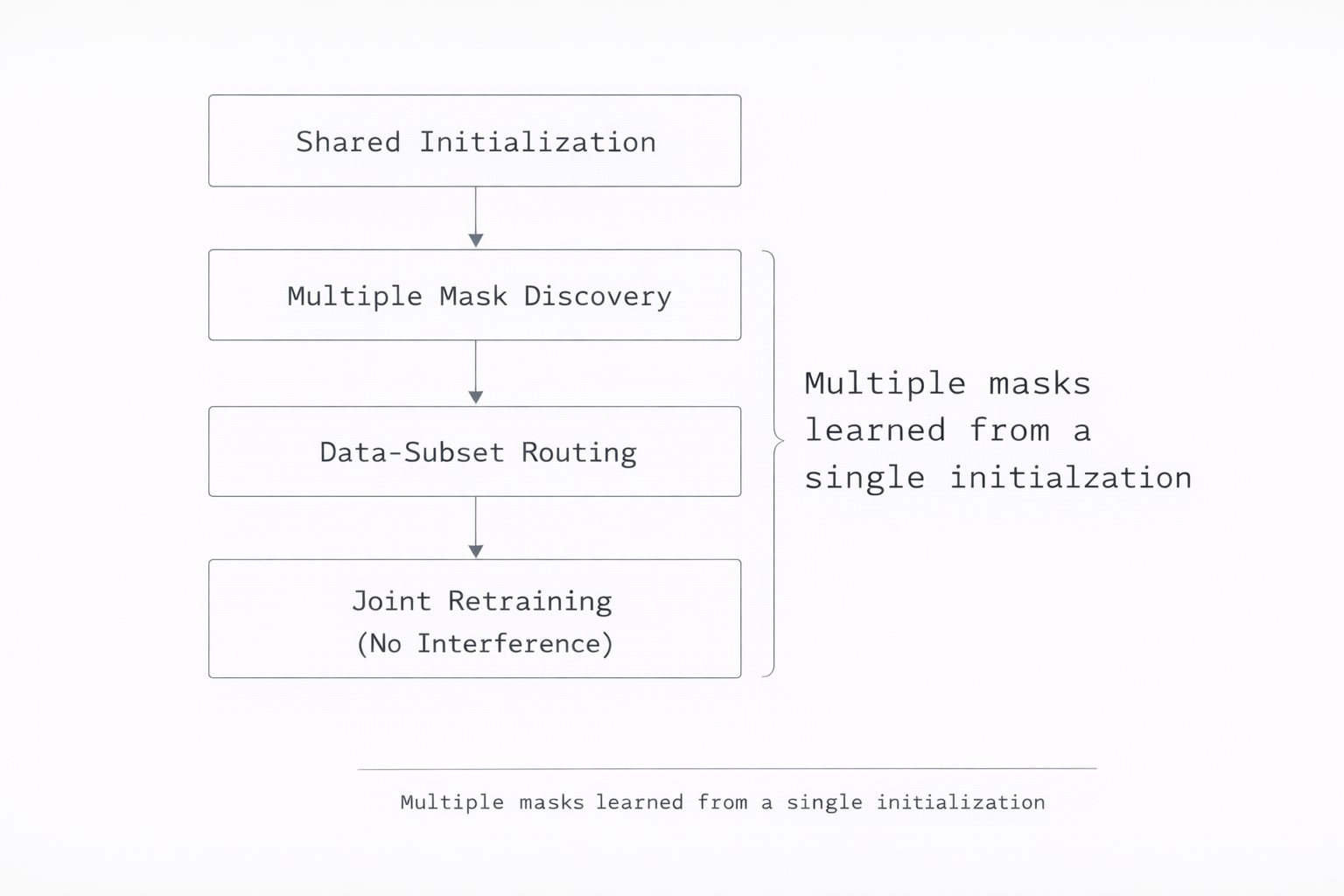
Here's what makes RTL different: Instead of pruning once globally, it learns MULTIPLE masks from the same initialization. Each mask specializes to a data subset (class, cluster, or environment). Then joint retraining refines them WITHOUT letting them interfere.