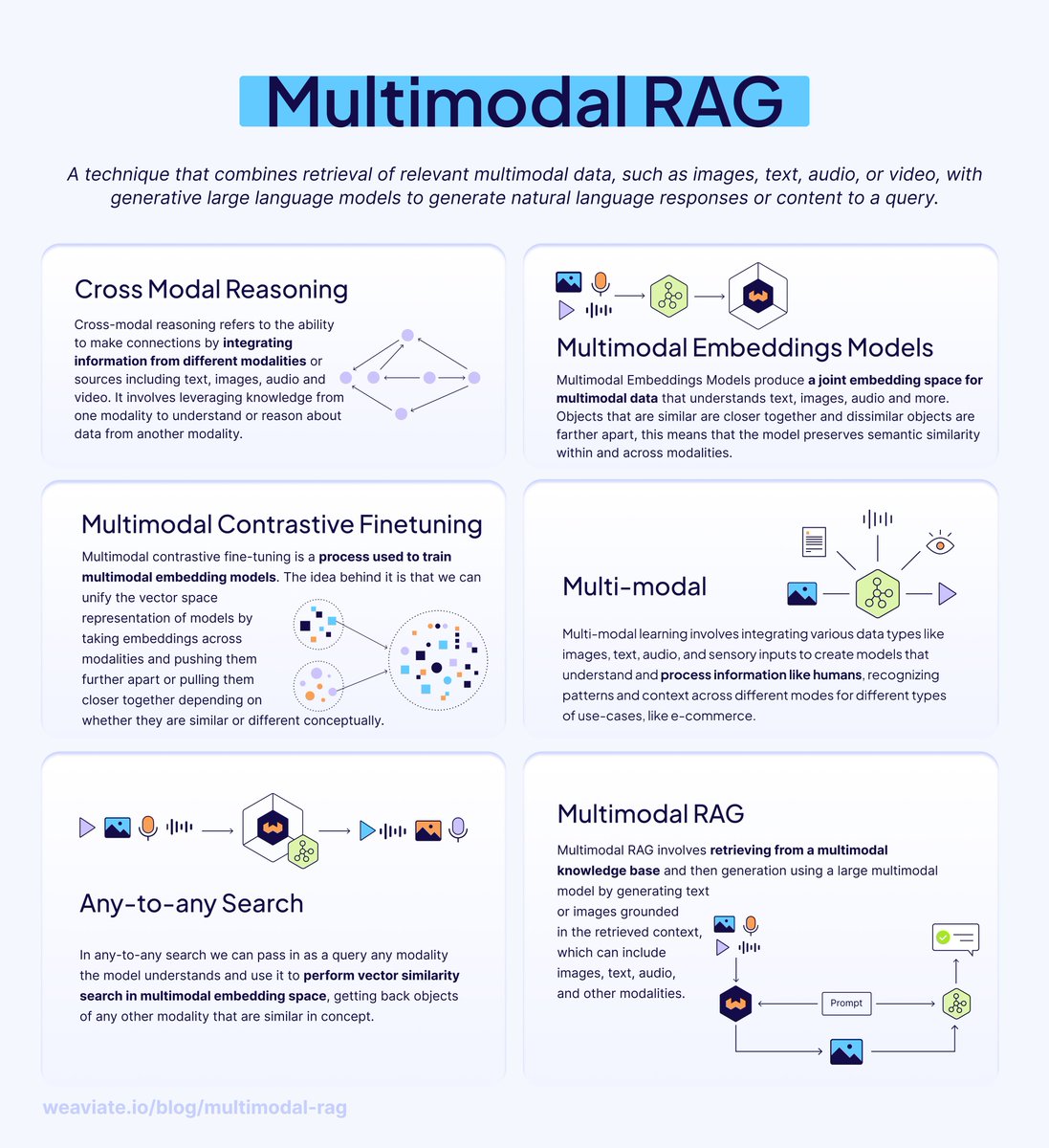
We process the world through all of our senses, not just text. Your AI shouldn't be stuck with just one. Humans don't process information in just one format – we digest information with photos, graphs, charts, and more to understand the world. Why should our AI systems be limited to text-only retrieval? Enter 𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗥𝗔𝗚 – retrieval augmented generation that works across multiple modalities like images and text. In this new Free @DataCamp course with @_jphwang, you’ll learn exactly how to go from simple LLM calls to multi-modal RAG workflows with Weaviate. Sign up here: datacamp.com/courses/end-to-… 𝗦𝗼, 𝗵𝗼𝘄 𝗱𝗼𝗲𝘀 𝗺𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗥𝗔𝗚 𝘄𝗼𝗿𝗸? 𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹𝘀 These models understand multiple data types in a 𝘫𝘰𝘪𝘯𝘵 𝘦𝘮𝘣𝘦𝘥𝘥𝘪𝘯𝘨 𝘴𝘱𝘢𝘤𝘦 – meaning similar concepts cluster together regardless of whether they're images, text, audio, or video. 𝗔𝗻𝘆-𝘁𝗼-𝗔𝗻𝘆 𝗦𝗲𝗮𝗿𝗰𝗵 Once modalities share an embedding space, you can search across them: • Use text queries to find relevant images • Search with audio to retrieve matching video clips • Find text descriptions from image inputs This is 𝗰𝗿𝗼𝘀𝘀-𝗺𝗼𝗱𝗮𝗹 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 in action – understanding relationships and context across different data types, just like humans do naturally. 𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗥𝗔𝗚 𝗶𝗻 𝗣𝗿𝗮𝗰𝘁𝗶𝗰𝗲 Instead of just retrieving text documents, multimodal RAG retrieves relevant images, diagrams, charts, or videos to augment LLM responses. This enables: • Visual question answering systems • Richer context for generation • More comprehensive and accurate outputs 𝗧𝗿𝗮𝗱𝗲-𝗼𝗳𝗳𝘀 𝘁𝗼 𝗰𝗼𝗻𝘀𝗶𝗱𝗲𝗿: • Requires aligned multimodal datasets (challenging to collect) • More complex model architectures than single-modality systems • Higher computational costs for training and inference 𝗚𝗲𝘁𝘁𝗶𝗻𝗴 𝘀𝘁𝗮𝗿𝘁𝗲𝗱 𝘄𝗶𝘁𝗵 𝗪𝗲𝗮𝘃𝗶𝗮𝘁𝗲: Weaviate already integrates with multimodal embedding models from Cohere, Google, NVIDIA, Hugging Face, and more. This allows you to use embeddings in a joint space, enabling nearVector and nearImage searches across both modalities. Download this free Advanced RAG guide for the full picture: weaviate.io/ebooks/advanced-…
→ View original post on X — @marcusborba, 2025-10-30 11:00 UTC