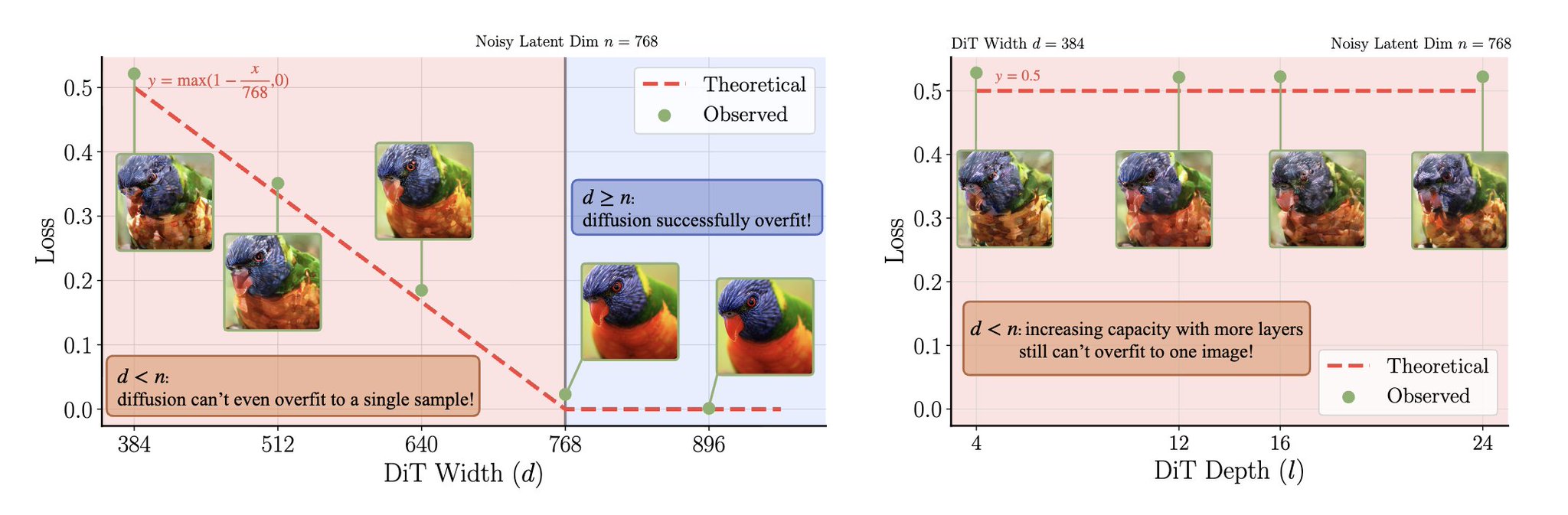
Diffusion Transformers struggled at first. Why? Their width was too small for RAE’s high-dimensional latents. The fix: scale width ≥ latent dimension. Once model width ≥ 768, DiT started converging instantly. Depth didn’t matter width unlocked training stability.
DiT Convergence: Width Over Depth Matters
By
–