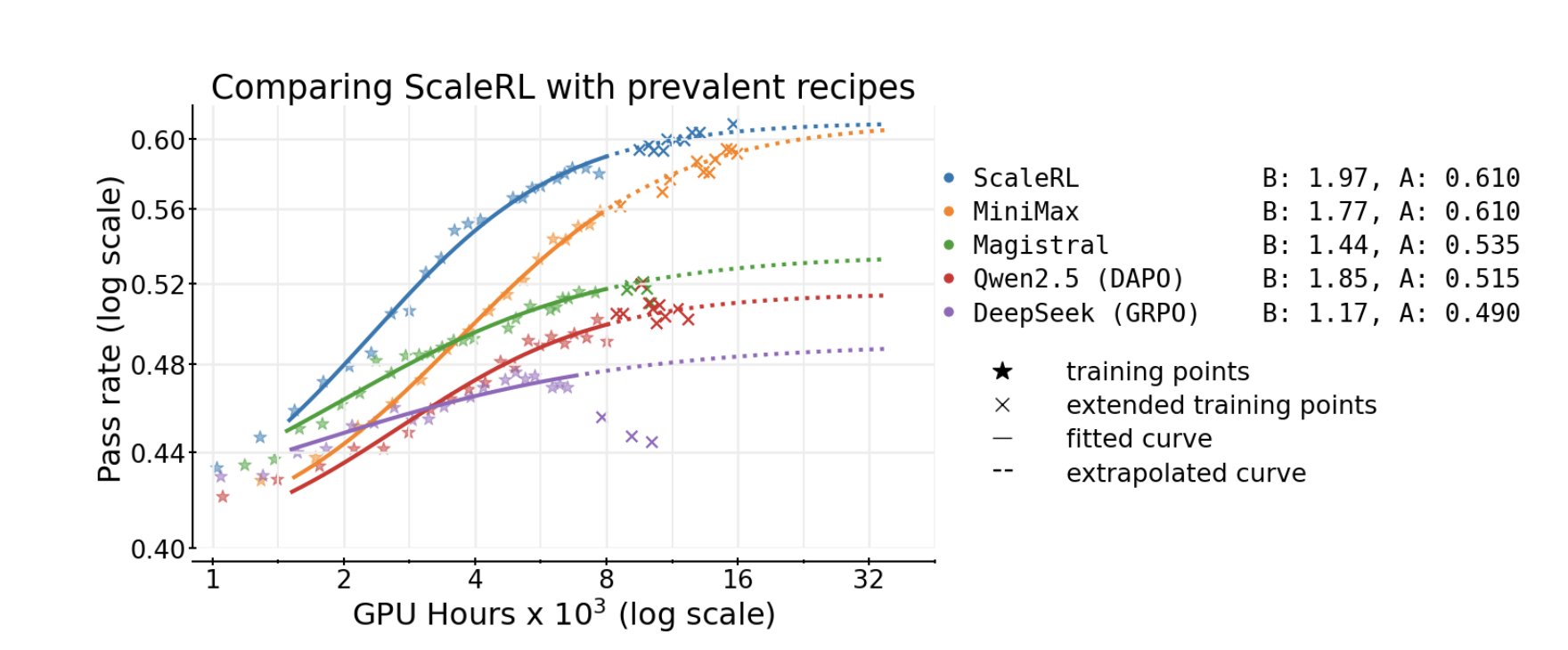
They tested this with 400,000 GPU hours across multiple RL recipes: DeepSeek (GRPO)
Qwen (DAPO)
Magistral
Minimax Result: only ScaleRL showed a stable, predictable trajectory. The others broke scaling laws entirely their curves collapsed.
ScaleRL outperforms in RL scaling tests
By
–